- Overview of algorithms for natural language processing
PubMed►
- Introduction to text analysis
Slides►
- Sentiment in patient reviews of clinicians (use instructor's
last name as password)
Read►
- General introduction to sentiment analysis of patient reviews Read►
- Priyal Makwana's Teach One Slides►
- Predicting who will attempt suicide
Slides►
Video►
YouTube►
Assignment
For this assignment you can use any statistical software.
Question 1: Use
the following corpus of training data, where comments have been classified as either complaint or praise. Clean the data using
Python and R codes for preparation of text for modeling. In particular, take the following steps to clean the data:
- Text Cleaning: Remove any irrelevant characters, symbols, or formatting from the text data.
- Tokenization: Split the text into individual words or tokens.
- Lowercasing: Convert all text to lowercase to ensure uniformity.
- Stopword Removal: Remove common words (e.g., "the," "and," "is") that don't carry much meaning.
- Stemming or Lemmatization: Reduce words to their base or root form (e.g., "running" to "run").
- Handling Special Characters: Deal with special characters and symbols as needed.
- Handling Missing Data: Address any missing or null values in the text data.
- Spelling corrections: Correct misspelled words, replace abbreviation with equivalent words
- Same Meaning: Use a thesarus to get to words or phrases with equivalent meaning
Once the data has been prepared, randomly select a target comment from
the training set (this step will need to be repeated for 30 comments
analyzed one at a time). Exclude the selected comment from the training set. Exclude
from the training set any comment that does not contain any of the words
in the target comment. Classify the comment using the following
procedures:
- ChatGPT. Use ChatGPT version 4.0 to classify the sentiment of the 30 randomly chosen comments; and ask for a probability that the
comment is a complaint.
- Transfer Probabilities. Calculate the probability of compaint associated with longest combination of words in both target
and training sentences:

- Feature Similarity. Calculate the probability of compaint associated with the target sentence as the average classification of
most similar comments. The similarity of the training comment and target comment is calculated using the following formula, where alpha
is a hyperparmeter that establishes the relative importance of missing words in the target or training comments:

- Weighted Logistic Regression. Regress classification of training sentences on the words, pair of words, and triplet of
words in the comment, using the similarity to target sentence as the weight. Predict the probability of the target comment being a
complaint using the following formula, where betas are the coefficients estimated in the regression:
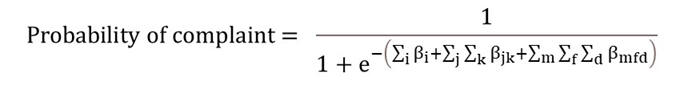
Resources for Question 1:
- Labeled training corpus
Data►
- Calculate the likelihood ratios associated with the longest matched phrase.
Slides►
YouTube►
- Madhukar Reddy Vongala's use of regression in sentiment analysis
Python►
- Blaine Donley's code and related data
- Vladimir Franzuela Cardenas's
Answer►
R-code►
- Amaljith Kuttamath's Teach One
YouTube►
Slides►
More
For additional information, please see the following links:
- Predicting psychosis through text analysis Read►
- Depression and speech Read►
- Context sensitive text analysis Read►
- Dependent Bayes procedure for text analysis PubMed►
This page is part of the HAP 819 course on Advanced Statistics organized by Farrokh Alemi, Ph.D.
Home► Email►