|
Analysis takes time and reflection. People must be lined up and their views sought. Ideas need to be sorted through. Data needs to be collected, stored and retrieved, examined and displayed. Completing the analysis, writing the report and presenting the findings takes time
and it should. Often at the end of this grueling effort, analysis identifies need for further inquiry and therefore it creates more delays
for decision makers. Policymakers and managers may find the analysis taking too long. They may have to decide without the full benefit of the analysis
and many do.
This chapter focuses on how analysis could be made faster without sacrificing its quality. Clearly, doing a thoughtful
analysis takes time. There is no point to hurry and produce a
sub-optimal analysis. But are there ways to complete analysis faster and
yet maintain the quality of the work? To understand what we can do to speed things up, one needs to understand what takes time. One
could imagine analysis consisting of distinct phases:
- Preparation
- Arrange for contracts and mandate to start
- Coordinate kick off meeting to clarify purpose & scope of the analysis
- Find relevant experts and decision makers
- Design study instruments and survey forms
- Data collection
- Collect observations
- Collect experts opinions
- Store data
- Analyze data
- Retrieve data
- Clean the data (classify data; check distribution and range of data, edit data)
- Examine accuracy of data (Check for errors in logic, check for errors in transfer of data)
- Examine if experts were in consensus
- Calculate expected values or model scores
- Calculate the correspondence between model and experts' judgments
- Presentation
- Distribute draft report
- Prepare presentation
- Get input from audience before meeting
- Present results at meeting
Each of these phases can be speeded up. Here is how this can be done.
Thorough preparation can lead to significant time savings in conduct of an analysis. This section lists specific recommendations regarding what should be done to be better prepared.
1. Draft the final report at the start
One of the simplest steps an analyst can take to reduce time from start of project (signing the contract) to the end of the project is to do a more thorough planning. In particular, it would be helpful to draft the final report (the introduction, the methods section, the results section), with all related tables and appendices at start of the project (Alemi, Moore, Headrick, Neuhauser, Hekelman, Kizys, 1998). Obviously the data will not be available to fill the report but one could put in the best guess for the data. This exercise speeds up analysis in several ways. First, it communicates precisely to decision makers what the final results will look like. It reduces confusion and saves the time spent on clarifying the procedures of the analysis. Second, it clarifies to the analyst what data are needed and identifies the sources of these data. Third, it clarifies what procedures should be followed to produce the Tables and Figures in the report. Obviously the data and the final report will be different but the exercise of putting the report together at the beginning of the meeting goes a long way in making sure that only relevant data are collected and time is not wasted on diversions.
A good example of drafting the report before the data is available is the process of generating automatic content on the web. The text of the report is prepared ahead of the data collection and portions of the report that depend on specific data are left as a variable to be read from a database. When the data are available, the final report is generated
automatically.
2. Avoid group kick-off meetings
Another step that can speedup preparations is to meet individually with decision
makers, even before the full kick-off meeting. Individual meetings are easier to arrange and require less coordination. Furthermore, as we discussed in the Chapter on Modeling Group's decisions, individual meetings facilitate later larger
face-to-face meetings.
3. Get access to the right experts
and through them to right data
A third step is to search for external experts that understand the situation clearly and do not require additional time to
orient themselves. On any topic, there are numerous experts available. Finding the right expert is difficult but important in saving time and gaining access to resources that only the expert has access to. Automated method of finding experts in a particular topic are widely available. One such tool is the Medline database. One could search a topic in Medline and find the authors who have published in the area. Most articles include contact information for the author. In this fashion, one could quickly put together a list of experts in a topic -- no matter how minutely it is defined. For example, suppose the analyst needs to examine merger between two hospitals. �
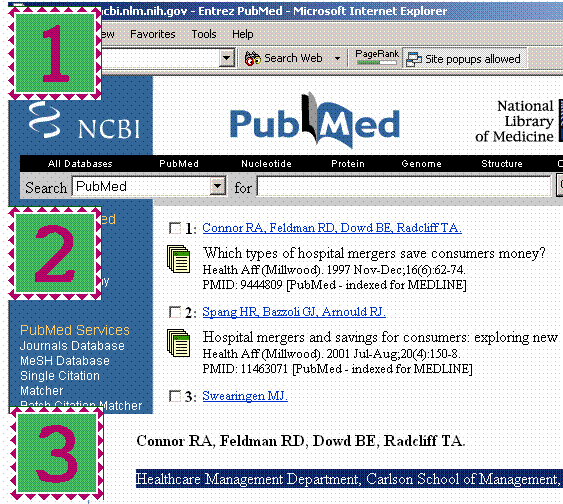
Figure 1: Three Steps to Identifying Relevant Subject Matter Experts
(1) Go to PubMed, (2) Search the literature and (3) Select key authors
In addition to searching the Medline databases, it maybe useful to search CRISP, a database of National Institute of Health funded projects
(see
http://crisp.cit.nih.gov/). CRISP is useful in identifying researchers who are currently collecting data. Many have thought through the issue and may have preliminary data that could be useful in the
analysis.
Finally, we also recommend searching Google's Scholar database for names of people who might have special expertise or knowledge of the issue being modeled. Google scholar is
at
http://scholar.google.com
Once a preliminary list has been identified, then the analyst contacts members of the list and asks them if they are aware of others who are doing research in this area, who might have access to specific databases, or who might be able to provide valid opinions on estimates needed in the analysis. The important advice is to use automated databases to search wide for one or two people who best fit the planned analysis. Choosing the right person can significantly improve access to various pieces of information and in the process reduce the time it takes to complete the analysis.
Speedup Data Collection
(This section is taken verbatim from Alemi, Moore, Headrick, Neuhauser, Hekelman, Kizys, 1998)
Often the data needed for the analysis is not available and must be collected or deduced from data that is available. There are at least five steps in which the analyst can reduce the data collection time.
4. Collect only the needed data
Too often people collect data that they do not need and will not analyze. This is absurd but many do it, some because they feel that certain information (e.g. demographics of the patients) must always be collected, others because they do not have a clear idea what they plan to do with the data. Every piece of datum, no matter how small adds to the length
of a survey and to the difficulty of administering it and in the end adds to the time it takes to conduct the analysis. We have already mentioned how preparing the final report ahead of time reduces the amount of data collected, as many pieces of data that do not make their way into the report are dropped from the data collection
plans.
5. Reduce the data collected by sampling
Many analysts collect too much data. This creates a large burden for administration of the surveys. The larger the number of people surveyed, typically the longer the time for completion of the analysis. Instead of focusing on large-scale surveys, it is better to focus on representative surveys. A sample of patients is chosen that seem to represent the population affect by the new process. These patients complete the survey and based on their responses inferences are made concerning the whole population. Only when sensitivity analysis shows that the datum plays an important role in the conclusions of the analysis, additional data are collected. One way to make sampling more efficient is to devise rules for expanding the sample. A small sample is drawn. If it leads to clear unequivocal conclusions, then no more data is collected. If the results are ambiguous, then a larger sample is drawn. Thus, for example, one may agree to sample 20 representative patients about their satisfaction with the new process. If less than
5% are dissatisfied, then no more samples are drawn. If between more than 5% of the respondents are dissatisfied; then, a larger sample of 50 patients is drawn. These methods of two-stage sampling save the number of patients that need to be contacted and thus reduce the time it takes to collect the information.
For a tutorial on adaptive statistical sampling see Bauer and Brannath (2004
). For additional reading in this area see Posch, Bauer and Brannath
(2003) or Schafer and Muller (2004).
6. Rely on subjective but numerical data
There are at least two sources for data. The first relies on your observation of the process and is called "objective." The second relies on the observations made by others and is referred to as "subjective." Note that by subjective data we do not mean the likes and dislikes of a person, which is after all idiosyncratic and unreliable. By subjective data, we mean relying on observations of others. Thus, a nurse saying that patients' satisfaction has improved is based on the nurse's observation of the frequency of the patients' complaints not on his or her likes and dislikes. When under time and resource pressures, subjective opinions maybe a reliable source of data that could replace the seemingly more "objective" observations made by the
analyst. An example of how subjective and objective data can be combined to
save time is presented later in this chapter.
7. Use subjective data for developing models & objective data for validating the model's accuracy
If experts specify the parameters of a model (e.g. the utility or probabilities in a Multi-attribute value model), then there is no need to put aside data for parameter estimation. So the need for objective data is reduced, not by just a little but radically. For example, severity indices can be constructed from subjective opinions or from analysis of objective data. Severity indices constructed from subjective opinions can be subsequently tested against objective data. When doing so, less data are needed because the subjective index has one degree of freedom while the objective multivariate approach has many. The number of degrees of freedom in a multivariate analysis is one minus the total number of variables. For each degree of freedom, one generally needs to include 10 times as many data items. Thus, if one has a 200 variable model, then there is 199 degrees of freedom and one needs approximately a database of 1990 cases. When experts specify the scoring of the 200 variable model, the scoring system maps all of the variables into a single score.
As a consequence, the degrees of freedom drops and the need for data is reduced. Thus, the 200 variable model, which previously required 1990 cases, can now be analyzed with 50 cases.
8. Plan for rapid data collection
One method of reducing data collection time is to put in place a number of plans for rapid response to specific questions that may be posed by the team. Thus, the analyst approaches employees close to the process and alerts them that the team plans to ask them a few questions. The exact nature of the question is not clear but the procedure used to send the question to them and collect the question is explained and perhaps even practiced. The individuals are put on notice about the need to respond quickly. When the need for data becomes clear, the analyst broadcasts the question, usually through a telephone message, and within a few hours collects the
response.
9. Use technology for data collection
Computers can now automatically call patients, find them in the community, ask them your questions, analyze the responses and fax the results to you. In one study, Alemi and Stephens (1992) asked a secretary and a computer to compete to contact "hard to reach" persons and ask them a few questions. One the average the secretary was able to do the task in 41 hours while the computer accomplished the same task in 9 hours. Technology can help overcome the difficulty of finding people. When you use technology to collect information from people, there is one added benefit. People are more likely to tell the truth to a machine than to a person. In surveys of drug use, homosexuality, and suicide risks, patients were more likely to report their activities to a machine than to a clinician, even though they were aware that the clinician will subsequently review the computer summary. Another advantage of collecting data through computer interviews is that it is immediately available and no time needs to be put into putting the data into the computer after its collection.
A number of reviews of effectiveness of various technologies for data
collection are available through Medline. Two articles to start with
are by Shapiro et al. (2004) and Newman et al. , (2002).
When data are available, several steps can be taken to make the analysis go
faster.
10. Clean the data & generate reports automatically
To speedup analysis, the analyst puts together procedures for cleaning the data even before the data is available. At the most simple level, the analyst prepares reports of distribution and range of each variable. Such reports can then be examined to see if there are unusual
entries. A computer program can then be prepared that will run various tests on the data to make sure the responses are within range (e.g., no one with negative age) and not conflicting with each other (e.g., no pregnant males). The computer can examine patterns of missing information and their reasons (i.e. not appropriate, data not available, data available but refusing to provide, etc.). The computer can examine patterns of data entry in previous cases to see if there is an unusual deviation from the pattern. This is typically done by calculating the mean of data items entered in previous cases and testing if the current data item is more than 3 standard deviations away from the mean. To assure integrity and accuracy of data, the computer can select a random number of cases for re-entry. The point is that procedures for cleaning the data can be automated as far as possible so that when data is available the analyst can rapidly
proceed.
Another alternative that has been made possible because of growth of web
services is to allow reports to be generated from data automatically.
First, the analyst drafts the report with all variables in the report linked
to a database. Then the analyst prepares a data collection procedure
which populates the database. Third, the computer cleans the data and
generates the report. Figure 2 shows these steps for a site Alemi
maintains on personal improvement. Clients who complete their personal
improvement report their success and failure on the web. The data are
collated by the computer, clean and stored in a web database. A report
is automatically generated from the data on the web so that current and
future clients can see the success rate of clients engaged in the personal
improvement effort. The report is available instantaneously after the
data is collected.

Figure 2: Report is Generated Automatically as Data
Becomes Available
11. Analyze emerging patterns before all data are available
Many readers are familiar with exit polling to predict results of elections. Same procedures can be used to anticipate data findings before complete data set is available. One very useful tool is to predict probability of an event from time it gets for the event to reoccur. In this fashion, early estimates of the datum can be made from even two re-occurrence of the event. If the event is rare, it takes a long time for it to reoccur. If not, it will reoccur in a short interval. BY examining the interval between the event, the probability of the event can be
estimated.
12. Use software
One way to conduct sensitivity analysis quickly is to use software designed to conduct decision analysis. Many of the existing software automatically conduct single and two variable sensitivity analysis.
Reviews of software for decision analysis are available online.
An analysis is not done until the sponsor examines the results. To speedup the presentation several steps can be taken.
13. Set up presentation meeting months in advance
Many decision makers are busy. To arrange for their time, make an appointment many months in advance. If a presentation date is set, it would create pressure to produce the findings on time.-
14. Present to each decision maker privately prior to the meeting
Even though a joint meeting is coming up, it is important to present to each decision maker separately and get their input so that the analysis can be revised in time for the meeting.
One of the most complicated concepts regarding speeding up decision analysis is the process of relying on subjective data to speedup data collection. To illustrate this point, we provide an example of how Gustafson combined experts opinions to make sense of existing objective data. Gustafson was asked to predict the impact of national health insurance programs on five low-income populations. The implementation of national health insurance (NHI) would have profound effects on people who currently rely on federal programs administered by the Bureau of Community Health Services (BCHS) in the Department of Health and Human Services. These groups include migrant farm workers, Native Americans, mothers and children needing preventive or special care, residents of medically underserved areas, people desiring family planning services, and those lacking adequate health insurance coverage. The unique circumstances of migrant workers and Native Americans necessitated the creation of special services responsive to their needs. If NHI results in termination of such assistance, the result could be a financial burden on current beneficiaries—and a reduction in their access to
care.
To accurately appraise changes that would occur under NHI, Gustafson had to find the utilization patterns of BCHS families and the unit cost of services consumed. He also had to ascertain the eligibility requirements and cost-sharing provisions of the NHI proposal. Finally, he had to determine which currently used services were included in the various NHI benefit packages. Primarily because of time constraints, he could not collect data and was confined to using the best available information.
Utilization patterns were created for individual family members (for each BCHS program) and stratified into appropriate age groups. Utilization patterns for individuals were then aggregated to achieve a family utilization description. The computer also determined extent of coverage under different NHI schemes and compared this figure to present costs. Before directing the computer to simulate some sample user families, Gustafson needed information on family characteristics, particularly the population’s socioeconomic and demographic status. These characteristics included such factors as number and size of families, age and sex of family members, employment status, whether employment was longer than 400 hours per year per employer, size of employing firm, income levels, and Medicaid status. This information was primarily collected from U.S. census data on BCHS
populations.
The simulation also required frequency distributions of utilization rates for each of a set of health services (such as hospitalizations or prenatal visits) for each existing BCHS project. Separate distributions were created for different levels of age and income. In many cases, these preliminary estimates were national averages for use of the particular service. In some cases, Gustafson decided that the best estimates of utilization came from regional sources, such as the Community Health Survey or the Mental Health Registry. The quality and reliability of these estimates were highly variable. Equally important, the available data reflected populations significantly different from BCHS users. Therefore, Gustafson brought together 80 experts, to estimate the missing parameters. Some of these experts were project directors with experience caring for BCHS clients at organizations with reliable data systems; others were researchers who had studied utilization of BCHS programs.
Gustafson showed the panel of experts utilization estimates from existing sources. Panelists were told the source of the data and asked to revise the estimates in light of their experience. Each panel was then divided into groups of four and asked to discuss their estimates. Each group within each panel concentrated on a single user population. For example, at the community health center meeting, one table represented rural health centers, another small urban centers, and two others large urban health centers. Following their discussions, each panelist made final, independent
estimates.
The revised utilization rates were aggregated into one set of estimates for each service. The aggregation across experts was done by weighting the estimates according to the proportion of the total BCHS user population each estimate represented. For instance, the estimates of rural health center panelists received less weight than large urban health centers because fewer people participate in rural
programs.
To simulate current costs to BCHS user families under NHI, Gustafson used expert-estimated distributions, the observed demographics and the various provisions of the NHI proposal to simulate what might happen. The simulation was run over a total of 500 families. A different set of families was, of course, generated for each BCHS program. Tables 1 depicts one sample
result.
| |
Current BCHS |
Under NHI |
|
Total cost of care |
$1,222 |
$1,222 |
|
Payments by BCHS |
64 |
|
|
Payments by third parties (Medicaid, Medicare, private insurance |
470 |
8 |
|
Payments by NHI |
- |
685 |
|
Premiums paid by users |
7 |
92 |
|
Deductibles, co-payments |
109 |
529 |
|
Total cost to users |
116 |
621 |
|
Table 1: Estimated Annual Costs for Community Health Centers |
The simulation was repeated under different NHI bills and proposals and for different BCHS populations. The key surprise finding was that NHI would raise barriers to access, not remove them, at least for several segments of the poor. A sensitivity analysis was done to see how much estimated variables had to change before the conclusions of the analysis would change. �
The point of this example was to show how quick analysis could be done through simulation and subjective probability. Although simulation is a powerful research tool, its utility has been limited by the absence of a strong database. This study suggested that subjective estimates from respected experts can be effective surrogates for solid empirical data.
This chapter has shown 14 ways of speeding up analysis without affecting the quality of the work. If analysis can be done quickly and accurately, then decision makers are more likely to use decision analysis.
1.
More thorough planning speeds up report creation. What is the
primary reasons why drafting the final report "at the start" speeds up the
analysis?
2.
Experts are naturally familiar with the subjects of their
expertise. But how could you as a person not familiar with the field find
the right expert? What is an automatic method of finding experts in a
particular topic?
3.
Researchers often overestimate the need for data. When is a small
sample adequate for surveying?
4.
Subjective and objective data can be used for research. When can
subjective opinions be a reliable source of data?
5.
Explain how a 200-variable model could be analyzed with only 50
cases as opposed to 10 times the number of variables in the model?
6.
What does �degrees of freedom� mean and how is this relevant to
rapid analysis?
7.
Why would automated data collection not only be faster, but more
accurate than data gathered by individuals?
8.
All statistical sources can have problems with missing data,
noise and outliers. What is the value of setting procedures for cleaning the
data even before it is collected?
9.
There are ways to anticipate data findings before a complete set
of data is available. How can the early estimate of the probability of an
event be assessed from two observations of the event?
10.
In the example give for Bureau of Community Health Services, what
data was subjective and not from primary sources?
Send your response by email to your instructor. Include both the
question and the answers in your response.
Alemi, F.; Stephens, R.C.; and Butts, J. Case management: A telecommunications practice model. In: Ashery, R.S., ed. Progress and Issues in Case Management. Rockville, MD: National Institute on Drug Abuse, 1992. pp.
261-273.
Alemi F, Moore S, Headrick L, Neuhauser D, Hekelman F, Kizys N. Rapid improvement teams. Jt Comm J Qual Improv. 1998
Mar;24(3):119-29.
Bauer P, Brannath W. The advantages and disadvantages of adaptive designs
for clinical trials. Drug Discov Today. 2004 Apr 15;9(8):351-7.
Newman JC, Des Jarlais DC, Turner CF, Gribble J, Cooley P, Paone D. The
differential effects of face-to-face and computer interview modes. Am J
Public Health. 2002 Feb;92(2):294-7.
Posch M, Bauer P, Brannath W. Issues in designing flexible trials.
Stat Med. 2003 Mar 30;22(6):953-69.
Schafer H, Muller HH. Construction of group sequential designs in
clinical trials on the basis of detectable treatment differences. Stat Med.
2004 May 15;23(9):1413-24.
Shapiro JS, Bessette MJ, Baumlin KM, Ragin DF, Richardson LD.
Automating research data collection. Acad Emerg Med. 2004 Nov;11(11):1223-8
- For another example of how subjective and objective data may be
combined see Marcin JP, Pollack MM, Patel KM, Ruttimann UE. Combining
physician's subjective and physiology-based objective mortality risk
predictions. Crit Care Med. 2000 Aug;28(8):2984-90. The study showed
that the combined model was more accurate than either the subjective or
the objective model. For more details click
here
- Frustration with slow pace of improvement projects has led to a
number of innovations to speed up the improvement process. In this
article, the author describes a 24 hour approach to improvement which
usually takes several months to complete. See Carboneau CE. Achieving
faster quality improvement through the 24-hour team. J Healthc Qual.
1999 Jul-Aug;21(4):4-10; quiz 10, 56. For more click
here
Others have also tried to speed up improvement efforts. For another
example see Panzer RJ, Tuttle DN, Kolker RM. 1995 Fast Track: cost
reduction and improvement. Qual Manag Health Care. 1997 Fall;6(1):75-83.
O�Malley lists 10 criteria for speeding up improvement efforts. See
O'Malley S. Total quality now! Putting QI on the fast track. Qual Lett
Healthc Lead. 1997 Dec;9(11):2-10. Abstract of this paper is available
here
- For an example of how policy analysis can be done faster by (1)
reducing the data collected and (2) using subjective opinions, see Peiro
R, Alvarez-Dardet C, Plasencia A, Borrell C, Colomer C, Moya C, Pasarin
MI, Zafra E. Rapid appraisal methodology for 'health for all' policy
formulation analysis. Health Policy. 2002 Dec;62(3):309-28. A summary of
this paper is available
here
- In Manitoba Canada, policy makers used well-organized data to
conduct rapid response to policy analysis requests. For more detail see
Roos LL, Menec V, Currie RJ. Policy analysis in an information-rich
environment. Soc Sci Med. 2004 Jun;58(11):2231-41.. The summary is
available
here
- See rapid analysis of
effectiveness of
Screening and Brief Intervention.
In groups of three, conduct a
time and motion study of how students complete the biweekly projects in this
class. At least, analyze three student projects to see what activities the
time was spent on. Identify the time various components of the activities
take and suggest how the work can be speeded up. The following table
suggests a set of task, though you may want to focus on other tasks as well:
|
Task |
Start
date |
End
date |
Total work hours |
|
1.
Preparation |
|
|
|
|
o
Receive assignment & understand work to be done |
|
|
|
|
o
Coordinate kick off meeting to clarify purpose & scope of the
work |
|
|
|
|
o
Find relevant experts and decision makers |
|
|
|
|
o
Design study instruments and survey forms |
|
|
|
|
2.
Data collection |
|
|
|
|
o
Collect observations |
|
|
|
|
o
Collect experts opinions |
|
|
|
|
o
Store data |
|
|
|
|
3.
Analyze data |
|
|
|
|
o
Retrieve data |
|
|
|
|
o
Clean the data (classify data; check distribution and range of
data, edit data) |
|
|
|
|
o
Examine accuracy of data (Check for errors in logic, check for
errors in transfer of data) |
|
|
|
|
o
Examine if experts were in consensus |
|
|
|
|
o
Calculate expected values or model scores |
|
|
|
|
o
Calculate the correspondence between model and experts'
judgments |
|
|
|
|
4.
Presentation |
|
|
|
|
o
Prepare report & distribute draft report |
|
|
|
|
o
Prepare presentation |
|
|
|
|
o
Get input from audience before meeting |
|
|
|
|
o
Present results at meeting |
|
|
|
In your report analyze the
total time lapsed between the start and end of each task and the total time
spent working on the task. Explain why there is a difference between lapsed
time and time worked on the task. For each task, describe what can be done
to reduce the difference between lapsed and worked time.
Describe the prerequisites of
each task by showing what needs to be accomplished before the task is
started. Use a table such as this in your report:
|
Task |
Cannot start until the following task is completed |
|
1.
Receive assignment & understand work to be done |
|
|
2.
Coordinate kick off meeting to clarify purpose & scope of the
work |
|
|
3.
Find relevant experts and decision makers |
|
|
4.
Design study instruments and survey forms |
|
|
5.
Collect observations |
|
|
6.
Collect experts opinions |
|
|
7.
Store data |
|
|
8.
Retrieve data |
|
|
9.
Clean the data (classify data; check distribution and range of
data, edit data) |
|
|
10.
Examine accuracy of data (Check for errors in logic, check for
errors in transfer of data) |
|
|
11.
Examine if experts were in consensus |
|
|
12.
Calculate expected values or model scores |
|
|
13.
Calculate the correspondence between model and experts'
judgments |
|
|
14.
Prepare report & distribute draft report |
|
|
15.
Prepare presentation |
|
|
16.
Get input from audience before meeting |
|
|
17.
Present results at meeting |
|
Review the task prerequisites
to identify the critical path (these are tasks that if delayed would delay
the completion of the project). Provide advice on how to start on critical
tasks sooner, what to do to remove the dependency of between the critical
task and its prerequisites.
Review the 14 recommendations
in this chapter and describe how they are the same or different from your
recommendations.
The following resources are
available for understanding this chapter:
|
