|
|
 |
|||||||||||
Schema DefinitionPreliminary Remarks
Previous session introduced the basic components of the XML markup syntax and showed how easily lists can be transformed into well-formed XML instance documents. That is the first step in the roadmap discussed in Introduction. This chapter shows how to proceed to the next step in the roadmap, namely, how to begin modeling the data. The XML technology that will be employed is the XML Schema Definition or XSD for short. What are Schemas?
A schema is an abstract definition of an object's characteristics and interrelationships.[1] When dealing with relational databases, the objects are data structures and their schemas are normally referred as ‘data models’. Their purpose is to document the database’s tables and columns, as well as how they are related to each other. An XSD, as its name implies, is also a schema. Its purpose is to document the elements of the XML document, their meaning, and their structure. As we can see, when dealing with structured data, we can accomplish pretty much the same, whether we use the relational data model approach, or we choose to go the XSD way. In either case the objects we are dealing with are data structures, and in both cases we are interested in specifying their semantics and syntax.
Before we go any further we need to qualify the general statement made above. There is an inherent mismatch between relational databases and XML documents. As we said in Chapter 1, every well-formed XML document is structurally equivalent to a ‘tree’. This means that elements can be nested inside other elements and they themselves can also be nested again. When nesting elements inside other elements the implication is that they stand in a parent-child relationship to each other.
Relational databases, on the other hand conform to ‘normalization rules’ and their basic data structures, namely, the database tables, do not allow nesting.[2] The relationships between database tables is handled via record identifiers which can point to a specific parent or child of a table.
Because we are assuming in this book that the results of data integration will be stored in relational databases, all the structures we are going to deal with will be relatively flat, and, therefore, readily map-able to individual tables in a database. In Chapter 4 we will briefly discuss how to handle nesting in XML documents and to how to flatten their structure so that it looks more like relational database objects.
W3C Schema Definition (XSD)
The World Wide Web Consortium (W3C) finalized its recommendations for XML Schema Definition (XSD) in 2001. It should be noted that the W3C XML Schema Definition is the latest in a series of proposals as well as commercial implementations for validation of instance XML documents. The older validation specification created for the Standard Generalized Markup Language (SGML), the parent of XML, is the Document Type Definition (DTD). In this book we will not cover the use of DTD’s, in part because it is becoming more of a legacy specification, and because the transformation and generation of DTD’s out of XSD’s is now supported by a variety of commercial tools. For a concise review of other alternatives to the W3C XML Schema see for example “XML Schema� by Eric van der Vlist, O’Reilly 2002.
Structure of the XSD
As we said in Section 2.1 above, the main purpose of an schema is to specify the structure and meaning of the elements that make up an instance XML document. In other words, we will use the XSD to express the following facts about the characteristics of our data:
Elements within an XSD
In an XSD, the XML tags of a document are referred to as elements. For instance, in the example shown in Chapter 1 (see Listing 04) the XML document looked like this:
This means that in an for this XML document we would need to specify five elements, namely, the root MedRecords, the record delimiter PatRec, and the contents of the record itself, Name, MedTest, and Date.
When an element contains only data but no other elements or attributes, its type is defined in an as simple. Otherwise its type is said to be complex. In the example we are considering we see that both the element MedRecords and the element PatRec are complex since MedRecords contains the element PatRec, and it in turn contains the elements Name, MedTest, and Date.
When an element is complex, i.e., its content is made up of other tags we can specify both the order in which they appear, as well as how many times they can appear. In the case of the element MedRecords we see that it can contain any number of instances of the element PatRec. The PatRec itself can contain its corresponding elements only once. If we want to lock in the order in which those elements should appear in our XML document we can specify that by listing them as a sequence. If the order is irrelevant then we can accept all of them in any order (see XSD listing below).
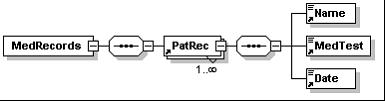
Figure 2.1 shows a pictorial representation of the analysis conducted so far generated with XML Spy. As shown therein, the element MedRecords can contain 1 or more instances of the element PatRec. The element PatRec itself can contain the elements Name, MedTest, and Date only once.
Figure 2.1. The Structure of the MedRecords Elements
Lastly, in the we can spell out the type of content of the simple elements Name, MedTest, and Date, by using the data types. In our example we may want to specify the contents as being either character strings or dates. Now that we have analyzed the instance XML document we can begin to write the XSD. The first thing we need to write down is the root element of the XSD. This is a fixed element of the form: <xs:schema xmlns:xs = "http://www.w3.org/2001/XMLSchema"> Next we can write the elements as described above. For the MedRecords we will specify that it is a complex type containing any number of instances of the element PatRec as follows:
<xs:element
name=
"MedRecords"> Next we can do the corresponding defintion for the element PatRec as follows:
<xs:element
name=
"PatRec"> Finally, we can define each of the elements included in PatRec as follows:
<xs:element
name=
"Name"
type="xs:string"/> The final piece is the closing tag for the root element of the schema, namely: </xs:schema> The complete listing looks as follows:
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"> Listing 2.1. XSD for the MedRecords.xml document Semantics of the ElementsIn the preceding example we have briefly outlined how the allows us to capture the elements of an XML document, how they relate to each other, as well as their syntax. The sample XSD, however, provides no information about the meaning of the elements. Although one could make educated guesses based on the names, the purpose of an XSD schema as we said above is also to provide a specification of what the data structures mean. The W3C specification provides a general element, namely, <xs:annotation>, which can include either the element <xs:documentation>, containing human readable content, or the element <xs:appinfo>, containing machine processable information. In this book we won’t discuss the latter one. So let’s go back to the elements of the MedRecords.xml and provide definitions for each one of them.
� As an aside, it should be kept in mind that when modeling source data we may need to refine the definitions as their scope is better understood. In turn, providing definitions early in the process is an effective method for avoiding misunderstandings which may be too costly to rectify at a later stage of data integration. The way to use <xs:annotation> and <xs:documentation> is then to add them for each element for which we want to capture their meaning.
<xs:schema
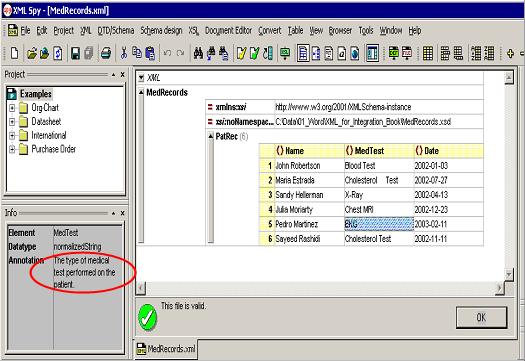
xmlns:xs="http://www.w3.org/2001/XMLSchema"> Listing 2.2. Annotated XSD for the MedRecords.xml document Figure 2.2 shows how XML design tools use annotations in an to provide the user contextual information about the data being examined.
Figure 2.2. Use of <xs:annotation> by XML Design Tools to Provide Context Basic Data TypesThis section gives a brief description of the major data types which can be specified in an for an element. The W3C XSD recommendation contains a large number of data types allowed but basically they all fit into three main categories: String Data Types, Numeric Data Types, and Date-Time Data Types. We are already familiar with the data type xs:string. This data type can accept not only the legal characters of Unicode and ISO/IEC 10646 but tab, line feed and carriage return as well, i.e., this data type does not force whitespace replacement. If one needs to prevent tab, line feed and carriage return as part of the content of an element, then its data type should be defined as xs:normalizedString. Note that such a data type will accpept multiple spaces as part of the content. To reject multiple leading, trailing and middle spaces one should use xs:token as the data type of a given element. The W3C recommendation further predefines other data types derived from xs:token but they are not pertinent to the scope of this book so they won’t be discussed. The next major group of data types are the numeric ones. The four primary types are xs:decimal xs:float and xs:double and xs:boolean. If one needs to have the most general form of numeric content xs:decimal is probably the best choice since it will validate any string of positive or negative numbers of any length with or without decimal point, as long as one does not use scientific notation, spaces between the numbers or delimiters (such as commas to indicate thousands). If the content of the element is in the form of mantissa plus exponent then one should use either xs:float (32 bit) or xs:double (64 bit). In addition one can enter special values in the content of an element that has either of these two data types such as ‘infinity’ (INF), ‘negative infinity’ (-INF), and ‘not a number’ (NaN). To specify flags (i.e., elements with only two values [0,1]) as the content of an element one should use xs:boolean. The last group of data types allowed under the W3C recommendation are those for dates and time. Due to the nature of calendars with their different month durations, leap years, etc., as well as the fact that we have varying time zones and summer saving hours this is one area where one needs a lot of care to avoid ambiguity. We have already seen the data type xs:date which uses the YYYY-MM-DD format. For elements with content containing time one can use xs:dateTime which uses the format YYYY-MM-DDThh:mm:ss. Derived Data TypesThe two most effective modes for creating new data types out of those already defined in the W3C recommendation are restrictions and enumerations. In the case of restrictions the original domain of the data type is narrowed. For example, if a health care provider sending or receiving information from another source wants to ensure that the dollar amount being charged (i.e., the content of the XML tag <ProcedureCost>) has a value of at least $15.00 but cannot exceed the value of $25,000.00 then one could create a new data type MedProcedureCost as follows:
<xs:simpleType
name=
"MedProcedureCost"> Once this is defined then the element <ProcedureCost> can use that new data type as follows: <xs:element name="ProcedureCost" type="MedProcedureCost"/> The complete schema would look like this:
<xs:schema
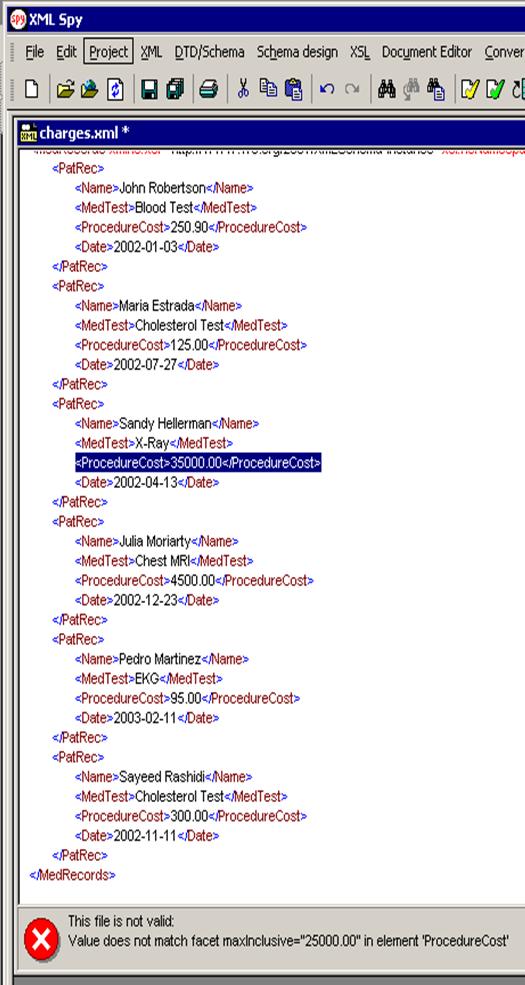
xmlns:xs="http://www.w3.org/2001/XMLSchema"> Listing 2.3. Example of a Derived Data Type via Restriction If we try to specify a value higher than the one the allows, for example by making the content of the <ProcedureCost> equal to $35,000.00 for patient Sandy Hellerman then we should expect the validation to fail.
<PatRec> This is in fact what happens. Figure 2.3 below shows how the XSD schema traps an error when the value of the charges exceeds the maximum value of $25,000.00.
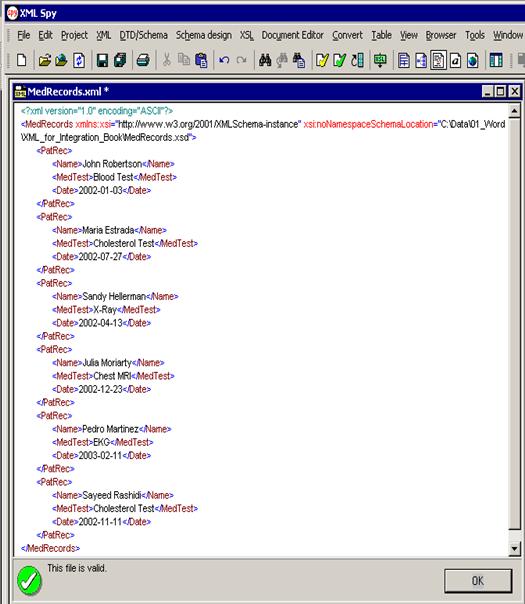
0� Figure 2.3. Error Trapped in Validation of Charges.xml Using XML Spy Validation with XSDm�As noted in Chapter 1, XML is an ideal means for transferring and displaying information in web-enabled applications. We also noted that when information is transferred and shared both the sender and recipient must have a common understanding of what the data means, i.e., its semantics and syntax and the preceding sections showed how to do that using XSD’s. Well-formed XML instance documents satisfy only the requirement that browsers and parsers can load them but by themselves cannot ensure conformance with the agreed semantics and syntax of a particular community of health care providers. XSD’s can—and are primarily used—to do that. Use of XSD’s in that role in turn makes processing of XML communications within information systems much easier, since, by acting as a kind of “data fire wall”, schemas eliminate the need to manually check every document or try to divine the meaning of its contents. Instead, health care providers with a requirement for data exchange can publish their validation schemas so that anyone trying to send to, or receive information from them can be assured that the data means what it is intended to mean and can load it in their legacy RDBMs. Last, but not least, XML validation schemas are also becoming integrated into other XML technologies such as those for performing SQL-like queries directly our of instance XML documents, e.g., XPath and XQuery, as well as in case tools for the design of entire Web-Services where they may alleviate the need for creating and maintaining low-level code for XML communications processing. Linking to the XMLOnce a schema is completed we need to assign it to the document we want to validate it with. This is done by inserting two attributes in the root tag of the instance XML document we want to validate as follows: <MedRecords xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="C:\Data\01_Word\XML_for_Integration_Book\MedRecords.xsd"> Once this is done one can use an application to validate the document. Figure 2.4 below shows the validation results using XML Spy.
Figure 2.4. Validation of MedRecords.xml Using XML Spy Comments on the Sample XSD
The analytical process described above for the creation of the made a couple of assumptions that need to be clarified. First, we approached its creation in a top-down mode starting with the root tag of the instance XML document and worked our way to the simple elements. In the process we defined the content of the complex type elements using the ref attribute. Note that in an the order in which its elements are defined is not important. We could have started in the reverse order, defining Name, MedTest, and Date first and then the rest. But the point to note is that when elements are defined in the manner we did above they are said to be defined ‘globally’ and can be reused anywhere in the XSD via the ref attribute. This is a very powerful technique whenever an attribute is semantically identical within the document and, therefore, needs to be defined only once but can be referenced multiple times. Listing 05 shows a case where the element CreationDate, intended to track when the record was created, is semantically equivalent irrespective of where it appears in the document:
<?xml version="1.0" encoding="ASCII" ?> Listing 2.5. Example of a Semantically Equivalent Element SummaryIn this section, we have learned the basic elements for building an XSD. We have also shown that XSD’s are, like other schemas, forms of data modeling, in that they capture the semantics and syntax of the data. Once these two components are specified we can begin to compare the data sources to see whether the contents mean the same, and how best to characterize them in terms of data types, whether they are mandatory or optional, as well as the number of times they can appear in an instance XML document. Last, but not least, we have also seen how to use an XSD to ‘validate’ an XML document. What do you know?Please complete the following problems and bring to class:w
<?xml version="1.0" encoding="UTF-8"?>
See a video on how to answer this question. Bring your work to class and be prepared to present it. PresentationsFollowing resources are available:
Narrated lectures require use of Flash. MoreIn this section you will find links to other resources.
|
|||||||||||