|
|
 |
|
Program Evaluation |
|
|
Large-scale evaluations of health and social service programs are commonly initiated to help policymakers make decisions on topics such as:
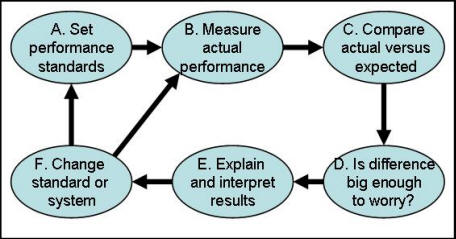
Not surprisingly, with this kind of interest, program evaluation has become a big business and an important field of study, Program evaluations are requested and funded by virtually every department of health and social services, not to mention many legislatures, governors, and city administrations. The basic concept of evaluating social and health care programs, as shown in Figure 1, is straightforward. A program is expected to meet certain performance standards (a). The program actually performs at a level (b) that may equal or exceed the standards or fall short because of flaws or unexpected environmental influences. Actual performance is compared to expected performance (c), and decisions are made about which, if any, of the discrepancies are worrisome (d). The findings are explained and interpreted to decision makers (e), and changes are introduced in either system performance or the expectations of it (f).
Figure 1: Schematic Representation of Program Evaluation While the basic concepts of evaluation are simple, actual implementation can be quite complex, and numerous evaluation techniques and philosophies have been introduced over the years (Alemi 1988). The major approaches are categorized as experimental, case study and cost/benefit analysis. Some researchers have advocated an experimental approach, with carefully designed studies using experimental and control sites, random assignment of subjects, and pre-and posttests. For example, Reynolds (1991) argues: "The more rigorous [true experimental] designs would be selected for studies that are at the other end of the continuum: that are lengthy, that are expensive, that are high-risk, that have multiple audiences, that are complex, about which little is known, that are difficult to measure, and that have a high chance of contamination." Variations on this experimental theme often remove the random assignment criterion. These “quasi-experimental” designs interject alternative explanations for findings (Campbell and Stanley 1966). Many process improvement efforts can be taught of as quasi-experimental studies (Benedetto 2003, Alemi, Haack and Nemes 2001). We don’t believe an experimental evaluation is always necessary, but when it is, random assignment must be an essential element of it. Another school advocates examining case studies (Barker and Barker 1994, Alemi 1988, Brown 2003), arguing that case studies are superior to experiments because of the difficulty of identifying criteria for experimental evaluation. Further, experiments require random subject assignment and pre- and posttests, both of which are impractical because they interfere with program operation. This school prefers using unobtrusive methods to examine a broad range of objectives and procedures and which are sensitive to unintentional side effects. This approach helps administrators improve programs instead of just judging them. Some case studies report on services offered and characteristics of their use, while others are less concerned with the physical world and emphasize the values and goals of the actors. Their reports tend to contain holistic impressions that convey the mood of the program. We believe that any evaluation must contain case studies to help people really understand and act on the conclusions. In the context of continuous quality improvement, the importance of case studies is emphasized by insisting to express the problem in the "customer's voice." Cost-benefit analysis evaluates programs by measuring costs and benefits in monetary terms and calculating the ratio of costs to benefits (Thompson 1980). This ratio is an efficiency statistic showing what is gained for various expenditures. There are many types of benefit analysis. Some analyses assume that the market price of services fairly and accurately measures program benefits; others measure benefits on the basis of opinion surveys. Variations on the cost-benefit theme involve comparisons that don’t translate everything into a dollar equivalent. The critical characteristic of those studies is an ability to compare what you get against what it costs to get it. Many Evaluations Are IgnoredAlthough program evaluations take a good deal of time and money, their results are often ignored (Hoffmann, Graf von der Schulenburg 2000, Drummond 1994). Even if interesting data are collected and analyzed, evaluations have no impact if their results are not directly relevant and timely to a decision. Often, evaluation reports present a variety of unrelated findings and thus confuse rather than clarify the decision maker’s choices. Despite calls for evidence-based practice, many clinicians ignore small and large evaluation studies (Zeitz, McCutcheon 2003). Evaluation studies with little impact generally began with a poor design. An evaluation can gain impact if the evaluator understands and focuses on the options, values, and uncertainties of the decision makers, To provide the kind of evaluation that supports policy formation, relevance to the decision must be designed in at the start, not tacked on at the end. Edwards, Gutentag, and Snapper (1975) wrote: “Evaluations, we believe, exist (or perhaps only should exist) to facilitate intelligent decision making ... an evaluation research program will often satisfy curiosity. But if it does no more, if it does not improve the basis for decisions about the program and its competitors, then it loses its distinctive character as evaluation research and becomes simply research” (p. 140). Decision-Oriented Evaluation DesignCertain design factors can increase the relevance of an evaluation to the actual decision making. The evaluators should:
In summary, we suggest that program evaluation should be tied to the decision-making process. The remainder of this chapter presents a nine-step strategy for such a decision-oriented evaluation design. We will clarify our presentation by referring to our evaluation of the nursing home quality assurance process (Gustafson et al. 1990). Continued rises in nursing home costs in the United States have stimulated increasing debate about how regulation can improve the industry. Some critics find the government ineffective at evaluating nursing homes (Winzelberg 2003) . These critics argue that current surveys of nursing home quality are too frequent, are too intensive, and have little relation to the health status and functional ability of nursing home residents. Gustafson et al. (1981) were asked to evaluate the process of surveying nursing home quality, and we use their experience to illustrate how a decision-oriented evaluation is done. Step 1. Identify the Decision MakersThe first step in planning an evaluation is to examine the potential users and invite them to help devise the plan of action. In the example, three groups might be expected to use the evaluation results: (1) the state government, to decide what program to implement; (2) the federal government, to decide whether to support the state’s decision and whether to transfer aspects of the project to other states; and (3) several lobbying groups (nursing home associations), to choose their positions on the topic. We identified individuals from each group, asked them to collaborate with our evaluation team, and kept them informed of progress and preliminary conclusions throughout the study. Step 2. Examine Concerns and AssumptionsNext we talked to the chosen decision makers (the program administrator and experts on the program, for example) to determine their concerns and assumptions, and to identify the potential strengths, weakness, and intended operations of the program. In the example, a decision maker who was concerned about the paperwork burden for quality assurance deemed the effort excessive and wasteful. A second decision maker was concerned with the cost of the quality assurance process and worried that it would divert money from resident care. A third was more concerned that quality assurance funds be distributed in a way that helped not only to identify problems but also to facilitate solutions. This person preferred to find solutions that would bring nursing homes into compliance with regulations. A fourth decision maker felt that the quality assurance process should attend not just to clients’ medical needs but also to their psychological and social ones. All these divergent objectives were important because they suggested where to look while designing a quality assurance process to address the decision makers’ real needs. We also helped identify and clarify each decision maker’s assumptions. These assumptions are important because, regardless of accuracy, they can influence decisions if not challenged. One decision maker believed the state must play a policing role in quality assurance by identifying problems and penalizing offending homes. Another person believed the state should adopt the role of change agent and take any necessary steps to raise the quality of care, even if it had to pay a home to solve its problems. We examined arguments for and against these philosophies about the role of government, and while we did not collect new data on these issues, our final report reviewed others’ research on the matter. Step 3. Add Your ObservationsAnother important method of examining a program is to use one’s own observations. The perceptions of decision makers, while very useful for examining problems in detail, do not prove that problems exist, only that they are perceived to exist. Thus, it is important to examine reports of problems to see that they are, indeed, real problems. We suggest that members of the evaluation team watch the system from beginning to end to create a picture of its functioning. A system analyst should literally follow the quality assurance team through a nursing home and draw a flowchart of the process. While observational studies are not statistically valid, they can add substantial explanatory power and credibility to an evaluation and allow us to explain failure and suggest improvements. A valuable side effect of such observations is to gather stories describing specific successes and failures. These stories have powerful explanatory value, often more than the statistical conclusions of the evaluation. The observations not only suggest how and where to modify the program, they also indicate areas that should be targeted for empirical data collection. Step 4. Conduct a Mock EvaluationThe next step is performing a mock evaluation, which is a field test to refine the evaluation protocol and increase efficiency. The mock evaluation keeps the decision maker informed and involved. Too often, decision makers first see the results of the evaluation when reading the final report. While this sequence probably allows enough time to produce a fine product, time alone guarantees neither quality nor relevance. We prefer informing the decision maker about our findings as the project proceeds, because, by definition, we are gathering information that could influence a decision. Decision makers will want access to this information, The mock evaluation lets the decision maker tell us which areas require more emphasis, allowing us to alter our approach while we have time. A mock evaluation is similar to a real one except that experts’ opinions replace much of the data. This “make-believe” evaluation helps estimate how much money and time are needed to complete the evaluation. It also changes the data collection procedures, sample size requirements (because we gain a more realistic estimate of variance in the data), and analysis procedures. Finally, the mock evaluation gives a preview of likely conclusions, which allows decision makers to tell whether the projected report will address the vital issues, as well as identify weaknesses in the methodology that still can be corrected. Critics of such previews wonder about the ethics of presenting findings that may be proven wrong by careful subsequent observation. But supporters counter by questioning the ethics of withholding information that could inform policy. These questions represent two extreme positions on a difficult issue. It is true that preliminary results may receive more credibility than they deserve. Moreover, decision makers may press to alter the evaluation design to prevent reaching embarrassing conclusions. We feel those dangers may be outweighed by the alternatives of producing irrelevant data, missing critical questions, or failing to contribute valuable information when it can help the policy debate. After the decision makers have read the mock report, we ask them to speculate about how its findings might affect their actions. As our evaluation team describes its preliminary findings, the decision makers will explain their possible courses of action and list other information that would increase the evaluation’s utility. It is important to make sure that evaluation findings lead to action. Decision makers can react in many ways to various findings. Some consider negative findings sufficient basis for changing their opinions and modifying the system, while others continue adhering to existing opinions. If our findings are unable to motivate the decision makers to change the system, this is a signal that we could be collecting the wrong data. At this point, we can decide to collect different data or analyze it more appropriately. The goal remains to provide information that really influences the decision maker’s choices. In the nursing home study, we observed several nursing home surveys, talked with interested parties, developed a flowchart of the process, and then asked the group to consider what they would do differently if the evaluation suggested that current efforts were indeed effective. We then repeated the question for negative findings on various dimensions. The discussion revealed that our experts, like others in the field, believed that existing quality assurance efforts were inefficient and ineffective, and these people expected the evaluation to confirm their intuition. But they felt evaluation findings would make a difference in the course of action they would follow. In other words, they were certain about the effectiveness of the current system but uncertain how to improve it. This is an important distinction, because an evaluation study that only gauged the effectiveness of the current system would confirm their suspicions but not help them act. What they needed was a study to pave the way for change, not just to criticize a system that was clearly failing. Our evaluation team and its advisory group at this point developed an alternative method of nursing home quality assurance that helped to reallocate resources by focusing on influencing the few problematic homes, not on the majority of adequate ones. We designed a brief nursing home survey to identify a problem home and target it for more intensive examination. Then we designed an evaluation to contrast this alternative approach to the existing method of evaluation. Thus, the mock evaluation led us to create an alternative system for improving nursing home quality, and instead of just evaluating quality of the current system, we compared and contrasted two evaluation systems. The mock evaluation is a preview that helps the decision makers see what information the evaluation will provide and suggested improvements that could be made in the design. And “showing off” the evaluation makes the decision makers more likely to delay their decision making until the final report is complete. Step 5. Pick a FocusFocus is vital. In the planning stage, our discussions with decision makers usually expand the scope of the upcoming evaluation, but fixed resources force us to choose which decision makers’ uncertainties to address, and how to do so. For example, further examination of the potential impact of the evaluation of nursing home quality assurance revealed a sequence of decisions that affected whether evaluation findings would lead to action. The state policymakers were responsible for deciding whether to adopt the proposed changes in quality assurance. This decision needed the approval of federal decision makers, who relied on the opinions of several experts as well as our evaluation. Both state and federal decisions to modify the quality assurance method depended on a number of factors, including public pressure to balance the budget, demand for more nursing home services, the mood of Congress toward deregulation, and the positions of the nursing home industry and various interest groups. Each of these factors could have been included in our effort, but we didn’t have the money to include all and we needed to select a few. Some factors in the decision-making process may be beyond the expertise of the evaluation team. For example, the evaluators might not be qualified to assess the mood of Congress. Although the evaluation need not provide data on all important aspects of the decision process, the choice not to provide data must be made consciously. Thus, we must identify early in the process which components to include and which to exclude as a conscious and informed part of evaluation planning. To those who think we are advocating sloppy analyses, we answer that evaluations often operate on limited budgets and thus must allocate resources to produce the best product without “busting the budget.” This means that specificity In some areas must be sacrificed to gain greater detail elsewhere. Step 6. Identify CriteriaNow the evaluation team and decision makers set the evaluation criteria, based on program objectives and proposed strengths and weakness of the program. (See Chapter 2 for a discussion of how to identify evaluation criteria, or “attributes”; see Chapter 6 to see how the analysis can be done using a group of decision makers.) The nursing home evaluation focused on a number of questions, one of which was the difference between the existing method of quality assurance and our alternative method. We used these criteria to evaluate this issue:
We created an evaluation design that divided the state into three regions. in the lower half of the state (and the most populous), nursing homes were randomly assigned to control and experimental conditions, after ensuring an equal number of proprietary nursing homes and nonprofit nursing homes, of similar sizes, treating similar patients, would be placed in each group. The. northern half of the state was divided into two regions, one receiving the new regulatory method and one not. This was done to observe how the management of the regulatory process would rate. Such random assignment greatly increased the credibility of the evaluation. A second aspect of design was the measures used. Previously a nursing home’s quality was judged on the basis of the number of conditions, standards, and elements found out of compliance. However, it was apparent that radical differences in severity of violations could take place within a level (e.g., element). It was decided to convene a panel of experts to rate numerically the severity of different violations. Tests of reliability between experts and over time demonstrated that the measures were good. Step 7. Set ExpectationsOnce the evaluation design is completed, we ask decision makers to predict the evaluation findings and express what they expect to find. This request accomplishes two things. First, it identifies the decision makers’ biases so we can design an evaluation that responds to them. Second, it gives a basis for comparing evaluation findings to the decision maker’s expectations, without attributing them to specific people. The impact of evaluation results is often diluted by hindsight. Reviewers might respond to the results by saying, “That is what I would have expected, but.... " Documenting expectations in advance prevents such dilution. In the nursing home example, decision makers expected that the alternative method would be slightly better than the current method, but they were surprised at how much better it performed. There were substantial cost savings as well as improvements in effectiveness. Because we had documented their expectations, their reaction was more akin to “Aha!” than to “That’s what we expected.” Step 8. Compare Actual and Expected PerformanceIn this phase we collect data to compare actual and expected performance. The observed findings are compared to decision maker's expected findings. For more information on data collection and statistical comparison, consult the many books on evaluation that cover these topics in detail. There are a variety of ways this can be done. One common way is to replace “actual” and “expected” performance comparisons with comparison of the control (or currently operating) and experimental (new) methods. Step 9. Examine Sensitivity of Actions to FindingsSensitivity analysis allows us to examine the practical impact of our findings. In this step, we asked decision makers to describe the various course of actions they would have taken if they had received specific evaluation findings. Then we asked them to consider what they would have done upon receiving different findings. Once we knew the threshold above which the actions would change, we calculated the probability that our findings could contain errors large enough to cause a mistake. Using the nursing home example, the evaluation might have revealed that one method of quality assurance was 5 percent more expensive than another. Decision makers might tell us that savings of 20 percent would induce them to change their decision. In this case, the decision makers would be asked identify a threshold, say 15 percent, above which they would change their decision. The evaluation team would then calculate the probability that the findings contained an error large enough to exceed the threshold. In other words, the team would state the chance that a reported 5 percent difference in cost is indeed a 15 percent difference in cost. Sensitivity analysis allows decision makers to modify their confidence in the evaluation findings. If the findings suggest that the reported practical differences are real and not the result of chance, then confidence increases. Otherwise, it decreases. ReferencesAlemi, F. 1988. “Subjective and Objective Methods of Program Evaluation.” Evaluation Review 11(6): 765—74. Alemi F, Haack MR, Nemes S. Continuous improvement evaluation: a framework for multisite evaluation studies. J Healthc Qual. 2001 May-Jun;23(3):26-33. Barker SB, Barker RT. Managing change in an interdisciplinary inpatient unit: an action research approach. J Ment Health Adm. 1994 Winter;21(1):80-91 Benedetto AR. Six Sigma: not for the faint of heart. Radiol Manage. 2003 Mar-Apr;25(2): 40-53. Brown P. Qualitative methods in environmental health research. Environ Health Perspect. 2003 Nov;111(14):1789-98 Campbell, D. T., and J. C. Stanley. 1966. Experimental and Quasi Experimental Design for Research. Chicago: Rand McNally. Drummond M. Evaluation of health technology: economic issues for health policy and policy issues for economic appraisal. Soc Sci Med. 1994 Jun;38(12):1593-600. Edwards, W., M. Gutentag, and K. Snapper. 1975. “A Decision-Theoretic Approach to Evaluation Research.” In Handbook of Evaluation Research, edited by E. L. Streuning and W. Gutentag. London: Sage Publications. Gustafson, D. H., and A. Thesen. 1981. “Are Traditional Information Systems Adequate for Policy Makers?” HCM Review (Winter). Gustafson, D. H., C. J. Fiss, Jr., and J. C. Fryback. 1981. “Quality of Care in Nursing Homes: New Wisconsin Evaluation System.” Journal of Long Term Care Administration 9 (2). Gustafson DH, Sainfort FC, Van Konigsveld R, Zimmerman DR. The Quality Assessment Index (QAI) for measuring nursing home quality. Health Serv Res. 1990 Apr;25(1 Pt 1):97-127. Hoffmann C, Graf von der Schulenburg JM. The influence of economic evaluation studies on decision making. A European survey. The EUROMET group. Health Policy. 2000 Jul;52(3):179-92. Reynolds J. A reconsideration of operations research experimental designs. Prog Clin Biol Res. 1991;371:377-94. Thompson, M. S. 1980. Cost Benefit Analysis for Program Evaluation. Beverly Hills, CA: Sage Publications. Winzelberg GS. The quest for nursing home quality: learning history's lessons. Arch Intern Med. 2003 Nov 24;163(21):2552-6. Zeitz K, McCutcheon H. Evidence-based practice: to be or not to be, this is the question! Int J Nurs Pract. 2003 Oct;9(5):272-9. PresentationsThe following resources are available to augment this lecture:
Biweekly ProjectDid you wake up today thinking that you needed to evaluate your services? Sure, why not. This section helps you decide whether you should and how you should do so. This is a think-it-through exercise that helps you decide what you should do when. For many of the questions there is no right or wrong answer. You are just expected to think through them and provide an answer.To proceed, you must have a specific service in mind. You can think of a service where you work or a service where you are a customer. But you must have a specific service in mind before proceeding. We are assuming that you are the manager of the service and the exercise is going to help you decide if you need to evaluate the service and how should you evaluate the service. The purpose of the activity is to help you become more aware of your own thoughts and reservations about conducting an evaluation of services.This exercise is in three parts. In the first part you think about the need for program evaluation. In part two you design a way of evaluating costumer’s satisfaction with your service. In the last part, you contrast your design with what was covered in the chapter and in this manner gain insights about some of the ideas expressed in the chapter. Part OneEvaluation takes time and money. To maintain independence, evaluation of impact of your service is best done by independent groups of investigators. Other evaluations, e.g. market studies, studies of patient satisfaction with your service, can be done in house. No matter who does the evaluation it still requires much planning, data collection, analysis and reporting. These activities could compete with your ability to focus your funds and time on organizing and improving the service. Sometimes evaluations are not done because the impact of the services are known or can be deduced from experience of others. The following questions attempt to understand why you may be ambivalent about conducting an evaluation of your services. What reservations do you have about conducting an evaluation of your service? Is there sufficient evidence in the literature or in the industry that suggests what you are doing will work and work well for patients of different backgrounds? If you think about it, evaluation could have many benefits. It could tell you and your clients that the service is effective in changing lives. It can tell you how to improve, and everyone – even the best among us – need to improve. It can help you convince third party payers to pay for your service. In this section, we ask you a number of questions about what the implications of not evaluating might be for you and your organization. Would it help your efforts to market your service if you knew more about people who are currently using your service and how they feel about it? Describe to me how survey of your clients can help you improve the service or improve the way it is marketed: Would patients who use your service, ask for the evaluation of the service?
By
the time patients come to the service, they have already evaluated our
reputation. Would your efforts to market the service to third party payers be hurt if you do not have data that the service works (meaning it saves money, improves access or improves quality of health services)? Inside your organization, would your career be affected if you do not have data that what you did was reasonable?
I
have a lot of support from different managers. As long as the service makes
money, we will be fine. What might go wrong if you fail to evaluate the service? Think through next six months to next 2 years. Describe a situation where you would say "Oops, I wished I had evaluated the impact of our service." Think harder. Is there some opportunity missed or negative consequences that may happen to you or to your organization as a consequence of failing to evaluate your service: Now that you have gotten this far how do you feel about evaluation and the type of questions that it should address?
No
need for evaluation. If so please
click here to proceed. Do you feel you know what you are doing or would you like help on how to evaluate your service?
I
have the experience and/or training in conducting evaluations. I do not need any
other help. Part TwoThis is part two of our think-it-through exercise. It is intended to help you evaluate satisfaction with your program services. As before, you must have a specific service in mind. Please do not proceed until you think of a specific service to evaluate.Think through what is the goal of the survey. Is it to convince purchasers that you have a good service? Sometimes purchasers are interested in repeated evaluation efforts that not only document problems but show a systematic effort to resolve problems. You may also engage in evaluation to help you find problems and fix it. In this case, you are not so much interested in reporting the problems you find but in fixing it and going on. There are many other reasons too. Tell us why you want to know if consumers are satisfied with your service? What is the real reason for wanting to know? One of the first issues you need to think through is who should do the work. Sometimes it is useful to engage a third party, which will help convince purchasers and other reviewers of the data that independent evaluations were done. If you evaluate your own efforts, there is always a suspicion that you may not report the whole story. In addition, some third party surveyors can benchmark your site against your competitors. For example, they can report that your service is among the top 5% of all services. Purchasers and consumers like benchmarked data. At the same time, asking others to help you evaluate is time consuming, expensive and may interfere with keeping your activities secret until it is publicly released. Given these issues, who do you think should evaluate your service and why? How often do
you want to evaluate satisfaction with your service? The answer to this question
in part depends on what question you want answered. If, for example, you want to
know which target group (people of certain age, sex, etc.) is most satisfied
with your service; then an occasional cross-section analysis is sufficient. In
cross-section analysis you survey the patients after exposure to your service.
Cross-section analysis can also be used to benchmark your service against other
services.
1. If you want to know whether exposure to your service changed the level of satisfaction patients have with their health plan, then you survey patients before and after exposure. 2. If you want to trace your improvement over time, you also need to stay with a longitudinal design. 3. If you are evaluating a service as you are building it and you are concerned with whether you are improving the patients' experience with your service, you also need a longitudinal design. Do you think that you may need to conduct a longitudinal or a cross-sectional study?
What is
sufficient evidence? There are many ways that satisfaction surveys could mislead
you. One possibility is that improvement in satisfaction may be related to other
events and not to your service. For example, patients' life style adjustments
may change their satisfaction with your service. To control for this type of
error it is important to contrast the improvement against a control group
exposed to another service. Another source of error could be that over time
respondents are getting to learn the system more and thus are more satisfied
with the services they are using. Dissatisfied individuals are unlikely to use
your service. Surveying only your users of your services may mislead you by
painting a rosy picture of clients' satisfaction. To control for these types of
errors it is important to contrast your services with others and to explicitly
look for customers who are not repeat users.
What do you want to ask? Some of the items in satisfaction surveys include the following:
(1) Overall
satisfaction with quality of services. You do not need to include all of the above items, nor do you need to limit your surveys to above items. There are many data banks of surveys. Keep in mind that standardized surveys allow you to benchmark your data against others. In contrast, doing your own survey helps you focus on patients' reactions to innovations in your effort. You can tailor your own surveys to your needs and therefore get more for the effort you are putting in. Please draft the questions you are planning to ask. It is neither necessary nor reasonable to survey all patients who use your service. You can sample. Sampling helps reduce the data collection burden on both the patients and the analyst. The size of the sample depends on what you are trying to conclude. If there is a lot of variability in patients' satisfaction with your service, you need larger samples. If you plan to compare your service with others and the two efforts are very similar, you need larger data. More important than the size of the survey is whether it represents the population. Getting many patients to respond does not correct for the lack of a representative sample. This is one case in which more is not always better. The point of sampling is to get a representative sample of people who receive your service. Small and large samples can both be representative. The key is to examine whether there are systematic differences among people who respond and those who do not. Here are some examples of non-representative designs:
We recommend that you randomly select a percentage of patients (not to be mistaken with randomly assigning patients to the service - a much harder task). This gives an equal chance that any particular patient may be included. In some circumstances you may wish to over-sample segments of the population. When segments of your population are small, you need to over-sample these segments so that you can obtain an accurate estimate of their satisfaction. Otherwise, too few of them will be in your sample to provide an accurate picture. Suppose that few teenagers visit your service. If you want to know about their satisfaction with your service, you will need to over sample teenagers. Thus, you may sample every 10 adults but every 5 teenagers. Over-sampling helps get a more accurate picture of small sub-groups of patients using your service. Think through the sampling strategy you wish to implement. Comment on why you expect that satisfied or dissatisfied clients will be reached in this fashion. Discuss how you plan to verify if your sample represents the population you want to generalize to. There are many choices available for data collection. You can have the survey done online and automatically. In these types of surveys, a computer calls or sends an email to your clients. You can also survey participants by mail, telephone or in person. The mode of conducting the survey may affect the results. Online, computerized telephone and mailed surveys are self-administered. Patients are more likely to report deviant social behavior in self-administered surveys. Online surveys (if connected to an automatic reminder) has a larger response rate than off line surveys. Online surveys are less expensive than offline surveys. Among offline surveys, face to face interviews are most expensive but allow for longer interviews. Given the tradeoffs of different modes of surveys, which is your preferred approach and why?
How you start your survey will have a lot to do with its success. We generally recommend that you alert the respondent that you plan to survey them before you actually send them a survey. This is preemptive reminder for people who forget to respond. In this fashion, the respondent will hear about you at least three to four times.
1. Invitation
to participate The invitation to respond to a survey should highlight:
Alert to upcoming survey includes an appreciation of respondent's willingness to participate, the day survey will be sent, and importance of timely respond. A reminder to non-participants often includes a repeated version of the survey. In online surveys, it is often necessary to make sure that respondents can answer questions quickly and without much download time. In fact, if you are tracing the person through their email, then it is best to have the survey page pasted to the email. In mailed surveys you should include a self-addressed, stamped envelope. No matter
how you do the survey, you should provide a real benefit for the respondent in
completing the survey. Altruism and voluntary requests get you far, but not far
enough. Think through what questions can you add that will make the respondent
feel happier, more cared for at the end of the survey. Many providers combine
satisfaction surveys with surveys of patients' health status or life style
appraisals. Patients get the benefit of a free health appraisal and evaluation
while they complete the satisfaction surveys. What language will you use for the survey? Keep in mind that your services are open to many people from different backgrounds and people are more likely to respond to a questionnaire prepared in their mother tongue.
Before you can analyze the data, you need to code the data (i.e. assign numbers to responses). When coding the data, you should include different codes for:
Analyze the missing data codes first. If you have a large
percent of your responses missing, then it is doubtful you can use the survey to
arrive at any conclusions. If certain patient groups tend to miss specific
questions, then you might have a systematic bias in your data. Another step taken in cleaning the data is to check for inconsistent or out of range responses. If responses 1 through 5 are expected but response 7 is given, then the response is considered out of range and is counted as erroneous responses. Similarly, if earlier in the survey the client indicated he is male and later that he is pregnant; then an inconsistent response is detected. Spend time cleaning the data. It will help you when it comes to interpreting the results. List below how would you prepare the data for analysis? To analyze the data begin with descriptive statistics.
Check each variable for skewness, range, mode and mean. Do the responses seem
reasonable? Next plot the data. Usually, satisfaction surveys have a number of
scales. Each scale is the average of responses to a number of questions. The
idea is that if there are different ways of asking the same question, then one
may have a more reliable scale. If so, then data may have a Normal distribution.
Do scale responses look like an upside down "U" shape? They should. Statistical
theory suggests that averages of more than four numbers will tend to have a
Normal distribution. Give a description of the final figures and tables will look like by preparing a mock up with hypothetical data: Part ThreePlanning for program evaluation requires you to think through your needs and activities. In the past two sections you did so. Now, explain how your plans are different from steps described in the reading in this chapter, what is missing from your plans that according to the chapter is important in decision analytic approaches to program evaluation. List all of the steps described in this chapter and for each step describe if it has been addressed in part one and two of your biweekly response. Does the decision analysis approach give you a perspective that might be missing otherwise from program evaluation?
Yes,
I became more sensitive to timing of decisions, need to focus on a decision
maker, need to focus on a specific decision with various options, need to
conduct sensitivity analysis and other issues . More
|
|