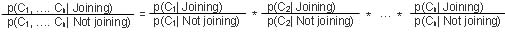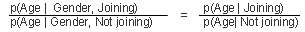|
|
 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Modeling UncertaintyThis section shows how to interview an expert and construct a model of his or her judgments using Bayesian probability models. Start with selecting the event to predict and the expert to interview. the expert will specify the clues helpful in making the prediction. For each clue level, the expert assesses a likelihood ratio. The probability of the target event is predicted from these ratios using the odds form of Bayes formula. The model, once created, is validated by comparing model predictions against experts' judgments. Statisticians can tell the future by looking at the past; they have developed several tools to forecast from historical trends future events. For example, future sales can be predicted based on historical sales figures. Sometimes, analysts must forecast unique events that lack antecedents. Other times, the environment has changed so radically that previous trends are irrelevant. In these circumstances, the traditional statistical tools are of little use. An alternative method must be found. In this section, we provide a methodology for analyzing and forecasting events when historical data are not available. The approach is based on Bayesian subjective probability models. To motivate this approach, suppose you have to predict demand for a special new type of HMO. HMOs are .group health insurance packages sold through employers to employees. HMOs require employees to consult a primary care physician before visiting a specialist; the primary physician has financial incentives to reduce inappropriate use of services. Experience with HMOs shows they can cut costs by reducing unnecessary hospitalization. Suppose we want to know what will happen if we set up a new type of HMOs where primary care physicians have email contact with their patients. At first, predicting demand for the proposed new HMO seems relatively easy, because there is a great deal of national experience with HMOs. But the proposed HMO uses technology to set it apart from the crowd: The member will initiate contact with the HMO through the computer, which will interview the member and send a summary to the primary care doctor, who would consult the patient's record and decide whether the patient should:
With the decision made, the computer will inform the patient about the primary physician’s recommends. If the doctor does not recommend a visit, the computer will automatically call a few days later to see if the symptoms have diminished. All care will be supervised by the patient's physician. Clearly, this is not the kind of HMO with which we have much experience, but let's blend a few more uncertainties into the brew. Assume that the local insurance market has changed radically in recent years ‑‑ competition has increased, and businesses have organized powerful coalitions to control health care costs. At the federal level, national health insurance is again under discussion. With such radical changes on the horizon, data as young as two years old may be irrelevant. As if these constraints were not enough, we need to produce the forecast in a hurry. What can we do? How can we predict demand for unprecedented product? Step 1. Select Target EventTo use the calculus of probabilities in forecasting an event, we need to make sure that the events of interest are mutually exclusive (the events cannot occur simultaneously) and exhaustive (one event in the set must happen). Thus, in the proposed HMO, we might decide to predict the following exhaustive list of mutually exclusive events:
The event being forecasted should be expressed in terms of the experts’ daily experiences and in terms they are familiar with. If we plan to tap the intuitions of benefit managers about the proposed HMO, we should realize they might have difficulty with our event types, which are described in terms of the entire employee population. If benefit managers are more comfortable thinking about individuals, we can calculate the four events from the probability that one employee will join. It makes no difference for the analysis how one defines the events of interest. It may make a big difference to the experts, however, so be sure to define the event of interest in terms familiar to them. Expertise is funny. If we ask experts about situations slightly outside their specific area or frame of reference, we often get erroneous responses. For example, some weather forecasters might predict rain more accurately than air pollution because they have more experience with rain. Therefore, it would be more reasonable to ask benefit managers about the probability of events, but focus on the individual, not the group:
Many analysts and decision makers, recognizing that real situations are complex and have tangled interrelationships, tend to work with a great deal of complexity. We prefer to forecast as few events as possible. In our example, we might try to predict the following events:
Again the events are mutually exclusive and exhaustive, but now they are more complex. The forecasts deal not only with applicants' decisions but also with the stability of those decisions. People may join when they are sick and withdraw when they are well. Turnover rates affect administration and utilization costs, so information about stability of the risk pool is important. In spite of the utility of such a categorization, we think it is difficult to combine two predictions and prefer to design a separate model for each ‑‑ for reasons of simplicity and accuracy. As will become clear shortly, we can use simpler methods of forecast with two events than when more events are possible. The events must be chosen carefully because a failure to minimize their number may indicate you have not captured the essence of the uncertainty. One way of ensuring that the underlying uncertainty is being addressed is to examine the link between the forecast event and the actions the decision maker is contemplating. Unless these actions differ radically from one another, some of the events should be combined. A model of uncertainty needs no more than two events unless there is clear proof to the contrary. Even then, it is often best to build more than one model to forecast more than two events. For our purposes, we are interested in predicting how many employees will join the HMO, because this is the key uncertainty that investors need to judge the proposal. To predict the number who will join, we can calculate p(Joining), the probability that an individual employee will join, If the total number of employees is n, then the number who will join is n * p(Joining). Having made these assumptions, let's return to the question of assessing the probability of joining. Step 2. Divide & ConquerWe suggested that demand for the proposed HMO can be assessed by asking experts, "Out of 100 employees, how many will join?" The suggestion was somewhat rhetorical, and an expert might well answer, "Who knows? Some people will join the proposed HMO, others will not ‑‑ it all depends on many other factors." Clearly, if posed in these terms, the question is too general to have a reasonable answer. When the task is complex, meaning that many contradictory clues must be evaluated, experts' predictions can be way off the mark. Errors in judgments may be reduced if we break complex judgments into several components or clues. Then the expert can specify how each clue affects the forecast and we can judge individual situations based on the clues that are present. We no longer need to directly make an estimate of the probability of the complex event. Its probability can be derived from the clues that are present and the influence these clues have on the complex judgment. In analyzing opinions about future uncertainties, we often find that forecasts depend .on a host of factors. In this fashion, the forecast is decomposed into predictions about a number of smaller events. In talking with experts, the first task is to understand whether they can make the desired forecast with confidence and without reservation. If they can, then we rely on their forecast and save everybody's time. When they cannot, we can disassemble the forecast into judgments about clues. Let’s take the example of the online HMO and see how one might follow our proposed approach. Nothing is totally new, and the most radical health plan has components that resemble aspects of established plans. Though the proposed HMO is novel, experience offers clues to help us predict the reaction to it. The success of the HMO will depend on factors that have influenced demand for services in other circumstances. Experience shows that the plan's success depends on the composition of the potential enrollees. In other words, some people have characteristics that dispose them toward. or against joining the HMO, As a first approximation, the plan might be more attractive to young employees who 'are familiar with computers, to older high-level employees who want to save time, to employees comfortable with delayed communications on telephone answering machines, and to patients who want more control over their care. If most employees are members of these groups, we might reasonably project good demand. If we have to make a prediction about an individual employee, one thing is for sure. Each employee will have some characteristics that suggest they are more likely to join the health plan and some that suggest the reverse. Seldom will we have a situation where all clues point to one conclusion. Naturally, in these circumstances the various characteristics should be weighted relative to each other before one can predict if the employee will join the health plan. How can we do so? Bayes' probability theory provides one way for doing so. Bayes' theorem is a formally optimal model for revising existing opinion (sometimes called prior opinion) in the light of new evidence or clues. The theorem states:
Bayes theorem states that the posterior odds after considering various clues is equal to the likelihood ratio associated with the clues times prior odds. Using the Bayes theorem, if C1 through Cn reflect the various clues, we can write the forecast regarding the HMO as:
The difference between p(Joining | C1, …. Cn) and p(Joining) is the knowledge of clues C1 through Cn. Bayes theorem shows how our opinion about an employee's reaction to the plan will be modified by our knowledge of his or her characteristics. Because Bayes' theorem prescribes how opinions should be revised to reflect new data, it is a tool for consistent and systematic processing of opinions. Step 3. Identify CluesIn the last section, we described how a forecast can be based on a set of clues. In this section, we describe how an analyst can work with an expert to specify the appropriate clues in a forecast. The identification of clues starts with the published literature. Even when we think our task is unique, it is always surprising how much has been published about related topics. To our surprise, there was a great deal of literature on predicting decisions to join an HMO, and even though these studies don't concern HMOs with our unique characteristics, reading them can help us think more carefully about clues. It is our experience that one seldom finds exactly what is needed in the literature. Once the literature search is completed, we strongly advocate using experts to identify clues for a forecast. Even if there is extensive literature on a subject, we cannot expect to select the most important variables or to discern all important clues. In a few telephone interviews with experts, one can find the key variables, get suggestions on measuring each one, and identify two or three superior journal articles. Experts should be chosen on the basis of accessibility and expertise. To forecast HMO enrollment, appropriate experts might be people with firsthand knowledge of the employees, such as benefit managers, actuaries in other insurance companies, and local planning agency personnel. It's useful to start talking with .experts by asking broad questions designed to help the experts talk about themselves. A good opening query might be: Analyst: "Would you tell me a little about your experience with employee choice of health plans?" The expert might respond with an anecdote about irrational choices by employees, implying that a rational system cannot predict everyone's behavior. Equally, the expert might mention how difficult it is to forecast, or how many years he or she has spent studying these phenomena. The analyst should understand what is occurring here. In these early responses, the expert is expressing a sense of the importance and the value of his or her experience and input. It is vital to acknowledge this hidden message and allow ample time for the expert to describe historic situations. After the, expert has been primed by recalling these experiences, the analyst asks about characteristics that might suggest an employee's decision to join or not join the plan. An opening inquiry could be: Analyst: "Suppose you were to decide whether an employee is likely to join but you could not contact the employee. I was chosen to be your eyes and your ears. What should I look for?" After a few queries of this type, ask more focused questions: Analyst: What is an example of a characteristic that would increase the chance of joining the HMO? We refer to the last question as a positive prompt because it elicits factors that would increase the chances of joining. Negative prompts seek factors that decrease the probability. An example of a negative prompt is: Analyst Describe an employee who is unlikely to join the proposed HMO. This distinction is important because research shows that positive and negative prompts yield different sets of factors. When Snyder and Swann (1978) asked subjects to identify clues for introversion and extroversion, they got differing responses. Though introversion and extroversion are opposite concepts and clues identifying one yield information about the other, the subjects identified two unrelated sets of clues. Thus, forecasting should start with clues that support the forecast, and then explore clues that oppose it. Then, responses can be combined so the model contains both sets. It is important to get opinions of several experts on what clues are important in the forecast. Each expert has access to a unique set of information; using more than one expert enables us to pool information and improve the accuracy of the recall of clues. Our experience suggests that at least three experts should be interviewed for about one hour each. After a preliminary list of factors is collected during that interview, the experts should have a chance to revise the list, either by telephone, by mail, or in a meeting. If time and resources allow, we prefer the Integrative Group Process for identifying the clues. Let us suppose that our experts identified the following clues for predicting an employee's decision to join:
Step 4. Describe Levels of Each ClueA level of a clue measures the extent to which it is present. At the simplest, there are two levels, presence or absence; but sometimes there are more. Gender has two levels, male and female. But age of employees may be described in terms of six discrete levels, each corresponding to a decade: younger than 21, 21‑30, 31‑40, 41‑50, 51‑60, older than 60. Occasionally we have continuous clues with many levels. For example, when any year between 1 and 65 is considered, we have at least 65 levels for age. In principle, it is possible to accommodate both discrete and continuous variables in a Bayesian model. In practice, discrete clues are used more frequently for two reasons: (1) experts seem to have more difficulty estimating likelihood ratios associated with continuous clues, and (2) in the health and social service areas, most clues tend to be discrete and virtually all other types of clue can be transformed to discrete clues. As with defining the forecast event, the primary rule for creating discrete levels is to minimize the number of categories. Rarely are more than five or six categories required, and frequently two or three suffice. We prefer to identify levels for various clues by asking the experts to describe a level at which the clue will increase the probability of the forecast event. Thus, we may have the following conversation:
Analyst: What would be an example of an age that would favor joining the HMO?
In all cases, each category or division should represent a different chance of joining the HMO. One way to check this would be to ask: Analyst: Do you think a 50‑year‑old employee is
substantially less likely to join than a 40‑year‑old? After much interaction with the experts, we might devise the following levels for each of the clues identified earlier:
In describing the levels of each clue, we also think through some measurement issues. For example, we use income, hence hourly wage, as a surrogate, even though it would be more accurate to survey the group. This decision rests on the fact that income data are accessible while a survey would be slow and expensive. But such decisions may mask a major pitfall. If income is not a good surrogate for value of time, we have wrecked our effort by taking the easy way out. Remember the story about the man who lost his keys in the street but was searching for them in his house. Asked why he was looking there, he responded with a certain pinched logic: "The street is dark ‑‑ the light's better in the house." The lesson is that surrogate measures must be chosen carefully to preserve the value of the clue. Step 5. Test for IndependenceConditional independence is an important criterion that can streamline a long list of clues (Schum 1965). Independence means that the presence of one clue does not change the value of any other clue. Conditional independence means that for a specific population, such as employees who join the HMO, presence of one clue does not change the value of another. .Conditional independence simplifies the forecasting task. The impact of a piece of information on the forecast, we noted earlier, is its likelihood ratio. Conditional independence allows us to write the likelihood ratio of several clues as a multiplication of the likelihood ratio of each clue. Thus, if C1 through Cn are the clues in our forecast, the joint likelihood ratio of all the clues can be written as:
Assuming conditional independence, the impact of two clues is equal to the product of the impact of each clue. Conditional independence simplifies the number of estimates needed for measuring the joint impact of several pieces of information. Without this assumption, evaluating the joint impact of two pieces of information requires more than two estimates. With it, the likelihood ratio of each clue will suffice. Let us examine whether age and sex are conditionally independent in predicting the probability of joining the HMO. Mathematically, if two clues, age and gender, are conditionally independent, then we should have:
This formula says that the impact of age on our forecast remains the same even when we know the gender of the person, Thus, the impact of age on the forecast does not depend on gender, and vice versa. The chances for conditional dependence increase along with the number of clues, so clues are likely to be conditionally dependent if the model contains more than six or seven clues. When clues are conditionally dependent, either one clue must be dropped from the analysis or the dependent clues must be combined into a new cluster of clues. If age and computer literacy were conditionally dependent, then either could be dropped from the analysis. As an alternative, we could define a new cluster with these levels:
The new clue is constructed by combining the levels of age and computer literacy. There are statistical procedures for estimating conditional dependence; however, the following behavioral procedure works quite well (Gustafson et al. 1973a):
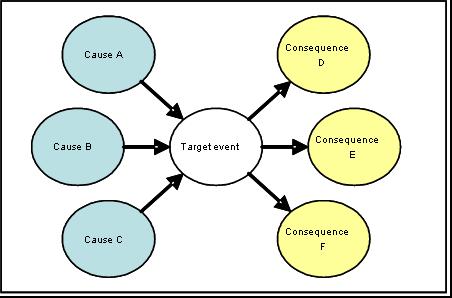
Experts will have in mind different, sometimes wrong, notions of dependence, so the words "conditional dependence" should be avoided. Instead, we focus on whether one clue tells us a lot about the influence of another clue in specific populations. We find that experts are more likely to understand this line of questioning as opposed to directly asking them to verify conditional independence. Analyst can also assess conditional independence through graphical methods. The decision maker is asked to list the causes and consequences (signs, symptoms or characteristics commonly found) of the condition being predicted. Only direct causes and consequences are listed, as indirect causes or consequences cannot be modeled through Odds form of Bayes probability model. A target event is written in a node at center of the page. All causes precede this node and are shown as arrows leading to the target node. All subsequent signs or symptoms are also shown as nodes that following the target event node (arrows leave the target node towards the consequences). Figure 1 shows 3 causes and 3 consequences for the target event.
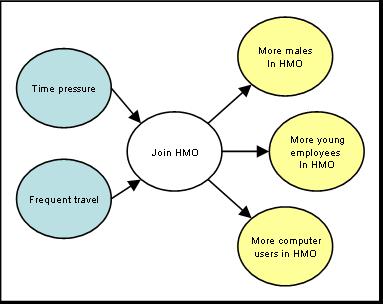
Figure 1: Causes & Consequence of Target Event Need to Be Drawn For example, in predicting who will join an HMO, the analyst might ask to draw the causes of people joining the HMO and the signs which will distinguish people who have joined from those who have not. A node is created in the center and called with the name of the target event. The decision maker might see time pressures as one reason for joining an online HMO and frequent travel as another reason for joining an online HMO. The decision maker might also see that as a consequence of joining the HMO, the HMO will be predominantly people who are male, computer literate and young. These are shown in Figure 2:
Figure 2: Two Causes & Three Signs (Consequences) of Joining the HMO To understand conditional dependencies implied by a graph, the following rules are applied:
If conditional dependence is found, the analyst has three choices. First, the analyst can ignore the dependencies among the clues. This would work well when multiple clues point to the same conclusion. But when this is not the case, ignoring the dependencies can lead to erroneous predictions. Second, the analyst could help the decision maker revise the graph or use different causes or consequences so that the model has fewer dependencies. This is often done by better defining the clues. For example, one could reduce the number of links among the bodes by providing a tighter definition of a consequence so that it only occurs through the target event. If at all possible, several related causes should be combined into a single cause to reduce conditional dependence among the clues used in predicting the target event. Finally, third, barring any revisions of the graph, the implication of conditional dependence in predicting the target event is the following:
For example, the Bayes formula for predicting the odds of joining the HMO can be presented as follows: Odds of joining = Likelihood ratio time pressure & travel frequency * Likelihood ratio age * Likelihood ratio gender * Likelihood ratio computer use * Prior odds of joining Step 6. Estimate Likelihood RatiosIn previous steps, we defined the forecast event and organized a set of clues that could be used in the forecast. Since we intend to use the Bayes' formula to aggregate the effects of various clues, the impact of each clue should be measured as a likelihood ratio. This section explains how to estimate likelihood ratios, but other approaches are possible (Huber 1974). To estimate likelihood ratios, experts should think of the prevalence of the clue in a specific population. The importance of this point is not always appreciated. A likelihood estimate is conditioned on the forecast event, not vice versa. Thus, the impact of being young (age less than 30) on the probability of joining the HMO is determined by finding the number of young employees among joiners. There is a crucial distinction between this probability and the probability of joining if one is young. The first statement is conditioned on joining the HMO, the second on being young. The definition of likelihood must be kept in mind‑it is conditioned on the forecast event, not on the presence of the clue. The likelihood of individuals younger than 30 joining is p(Younger than 30 | Joining) , while the probability of joining the HMO for a person younger than 30 is p(Joining l Younger than 30). The two concepts are very different. A likelihood is estimated by asking questions about prevalence of the clue in populations with and without target event. For example, for joining the HMO, we ask: Analyst: Of 100 people who do join, how many are younger than 30? Of 100 people who do not join the HMO, how many are younger than 30? The ratio of ‑the answers to these two questions determines the likelihood ratio associated with being younger than 30. This ratio could be estimated directly by asking the expert to estimates the odds of finding the clue in population with and without target event. For example, we could ask: Analyst: Imagine two employees, one who will join the HMO and one who will not. Who is more likely to be younger than 30? How many times more likely? We estimate the likelihood ratios by relying on experts' opinions, but the question naturally arises about whether experts can accurately estimate probabilities. Before answering we need to emphasize that accurate probability estimation does not mean being correct in every forecast. For example, if we forecast that an employee has a 60 percent chance of joining the proposed HMO but the employee does not join, was the forecast inaccurate? Not necessarily. The accuracy of probability forecasts cannot be assessed by the occurrence of a single event. A better way to check the accuracy of a probability is to check it against observed frequency counts. A 60 percent chance of joining is accurate if 60 of 100 employees join the proposed HMO. A single case reveals nothing about the accuracy of probability estimates. Systematic bias may exist in subjective estimates of probabilities (Lichtenstein and Phillips 1977; Slovic, Fischhoff, and Lichtenstein 1977). Research shows that subjective probabilities for rare events are inordinately low, while they are inordinately high for common events. These results have led some psychologists to conclude that cognitive limitations of the assessor inevitably flaws subjective probability estimates. For example, Hogarth (1975) concludes: "Man is a selective, sequential information processing system with limited capacity, he is ill‑suited for assessing probability distributions." Alemi, Gustafson, and Johnson (1986) argue that accuracy of subjective estimates can be increased through three steps. First, experts should be allowed to use familiar terminology and decision aids. Distortion of probability estimates can be seen in a diverse group of experimental subjects, but not among all real experts. For example, meteorologists seem to be fine probability estimators (Winkler and Murphy 1973). Weather forecasters are special because they assess familiar phenomena and have access to a host of relevant and overlapping objective information and judgment aids (such as computers and satellite photos). The point is that experts can reliably estimate likelihood ratios if they are dealing with a familiar concept and have access to their usual tools. In this regard, Edwards writes: If substantive experts are indeed allowed the time and the necessary tools (e.g., paper and pencil), they can accurately assess probabilities. Granted that assessed probability is not precise to the third digit, it nevertheless is a systematic and coherent assessment of the individual's belief. (See Edward's comments following Hogarth's,1975 article.) A second way of improving experts' estimates is to train them in selected probability concepts (Lichtenstein and Fischhoff 1978). In particular, experts should learn the meaning of a likelihood ratio. Ratios larger than 1 support the occurrence of the forecast event; ratios less than 1 oppose the probability of the forecast event. A ratio of 1‑to‑2 reduces the odds of the forecast by half; a ratio of 2 doubles the odds. The experts also should be taught the relationship 'between odds and probability. Odds of 2‑to‑1 mean a probability of 0.67; odds of 5‑to‑1 mean a probability of 0.83; odds of 10‑to‑1 mean a probability of an almost certain event. The forecaster should walk the expert through and discuss in depth the likelihood ratio for the first clue before proceeding. We have noticed that the first few estimates of probability can take four or five minutes each, as many things are discussed and modified. Later estimates often take less than a minute. A third step for improving experts' estimates of probabilities is to rely on more than one expert and on a process of estimation, discussion, and re-estimation. This method can reduce inaccuracies by as much as 33 percent compared to individual estimates (Gustafson et al. 1973b). Relying on a group of experts increases the chance of identifying major errors. In addition, the process of individual estimation, group discussion,. and individual re-estimation reduces pressures for artificial consensus while promoting information exchange among the experts. Step 7. Estimate Prior OddsAccording to Bayes' formula, forecasts require two types of estimates: likelihood ratios associated with specific clues, and prior odds associated with the target event. Prior odds can be assessed by find in the prevalence of the event. In a situation without a precedent, prior odds can be estimated by asking experts to imagine the future prevalence of the event. Thus, the odds for joining may be assessed by asking: Analyst: Out of 100 employees, how many will join? The response to this question provides the probability of joining, p(Joining), and this probability can be used to calculate the odds for joining: Odds for joining = p(Joining) / [1 -p(Joining)] When no reasonable prior estimate is available, we prefer instead to assume arbitrarily that the prior odds for joining are 1‑to‑1, and allow clues to alter posterior odds as we proceed. Step 8. Develop ScenariosDecision makers use scenarios to think about alternative futures. The purpose of forecasting with scenarios is to make the decision maker sensitive to possible futures. The the decision maker can work to change the possible futures. Many future predictions are self-fulfilling prophecies ‑‑ a predicted event happens because we take steps to increase the chance for it to happen. In this circumstance, predictions are less important than choosing the ideal future and working to make it come about. Scenarios help the decision maker choose a future and make it occur. Scenarios are written as coherent and internally consistent narrative scripts. The more believable they are, the better. Scenarios are constructed by selecting various combinations of clue levels, writing a script, and adding details to make the group of clues more credible. An optimistic scenario may be constructed by choosing only clue levels that support the occurrence of the forecast event; a pessimistic scenario combines clues that oppose the event's occurrence. Realistic scenarios,, on the other hand, are constructed from a mix of clue levels. In the HMO example, scenarios could describe hypothetical employees who would join the organization. A customer most likely to join is constructed by assembling all characteristics that support joining: A 29‑year‑old male employee earns more than $60,000. He is busy and values his time; he is familiar with computers, using them both at work and at home. He is currently an HMO member, though not completely satisfied with it. A pessimistic scenario describes the employees least likely to join:
More realistic scenarios combine other clue levels:
A large set of scenarios can be made by randomly choosing clue levels and then asking experts to throw out impossible combinations. To do this, first write each clue level on a card and make one pile for each clue. Each pile will contain all the levels of one clue. Randomly select a level from each pile, write it on a piece of paper, and return the card to the pile. Once all clues are represented on the piece of paper, have an expert check the scenario, and discard scenarios that are wildly improbable. If experts are evaluating many scenarios (perhaps 100 or more), arrange the scenario text so they can understand them easily and omit frivolous detail. If experts are reviewing a few scenarios (perhaps 20 or so), add detail and write narratives to enhance the scenarios' credibility. Because scenarios examine multiple futures, they introduce an element of uncertainty and prepare decision makers for surprises. In the example, the examination of scenarios of possible customers helped the decision makers understand that large segments of the population may not consider the HMO desirable. This led to two changes. First, a committee was assigned to make the proposal more attractive to segments not currently attracted to it. This group went back to the drawing board to examine the unmet needs of people unlikely to join. Second, another committee examined how the proposed HMO could serve a small group of customers and still succeed. Sometimes forecasting is complete after we have examined the scenarios, but if the decision makers want a numerical forecast, we must take two more steps. Step 9: Validate the ModelAny subjective probability model is in the final analysis just a set of opinions, and as such should not be trusted until it passes vigorous evaluation. The evaluation of a subjective model requires answers to two related questions: (1) Does the model reflect the experts' views? and (2) Are the experts' views accurate? To answer the first question, design about 30 to 100 scenarios, ask the expert to rate each, and compare these ratings to model predictions. If the two match closely, then the model simulates the expert's judgments. For example, we can generate 30 hypothetical employees and ask the expert to rate the probability that each will join the proposed HMO. To help the experts accomplish this, we would ask them to arrange the cases from more to less likely, to review pairs of adjacent employees to see if the rank order is reasonable, and to change the rank orders of the employees if needed. Once the cases have been arranged in order, the experts would be asked to rate the chances of joining on a scale of 0 to 100. Table 1 shows the resulting ratings. For each scenario, we would use the Bayes' model to forecast whether the employee will join the HMO. Table 1 also shows the resulting predictions.
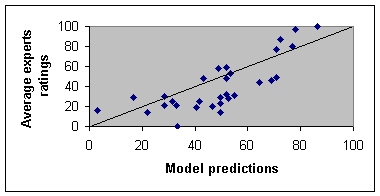
Table 1: Two Experts Ratings & Bayes Forecast on 30 Hypothetical Scenarios Next we compare the Bayes prediction to the average of the experts' ranking. If the rank order correlation is higher than 0.70, we would conclude that the model simulates many aspects of the expert's intuitions. Figure 3 shows the relationship between model predictions and average experts' ratings.
Figure 3: Validating a Model by Testing If It Simulates Experts' Judgments The straight line shows the expected relationship. Some differences between the model and the experts should be expected, as the experts will show many idiosyncrasies and inconsistencies not found in the model. But the model's predictions and the experts' intuitions should not sharply diverge. One way to examine this is through correlations. The model predictions and the average of the experts' ratings had a correlation of 0.79. If the correlation is lower than 0.5, then perhaps the expert's intuitions have not been effectively modeled, in which case the model must be modified, the likelihood ratios might be too high, or some important clues might have been omitted. In this case, the correlation is reasonable high enough that we can conclude that the model has simulated the experts' judgments. The above procedure leaves unanswered the larger and perhaps more difficult question of the accuracy of the expert's intuitions. Experts opinions can be validated if they can be compared to observed frequencies, but this is seldom possible (Howard 1980). In fact, if we had access to observed frequencies, we would probably not bother consulting experts to create subjective probability models. In the absence of objective data, what steps can we take to reassure ourselves regarding our experts? One way to increase our confidence in expert opinions is to use several experts. If experts reach a consensus, then we feel comfortable with a model that predicts that consensus. Consensus means that experts, after discussing the problem, independently rate the hypothetical scenarios close to one another. One way .of checking the degree of agreement among experts' ratings of the scenarios is to correlate the ratings of each pair of experts. Correlation values above 0.75 suggest excellent agreement; values between 0.50 and 0.75 suggest more moderate agreement. If the correlations are below 0.50, then experts differed, and it is best to examine their differences and redefine the forecast. In the example above the two experts had a correlation of 0.33, which suggests that they did not agree on the ratings of the scenarios. In this case, it would be reasonable to investigate the source of disagreement and arrive at a better consensus among the experts. Alternatively, if experts are unlikely to resolve their differences, then each can be modeled separately. Some investigators feel that a model, even if it predicts the consensus of the best experts, is still not valid because they think that only objective data can really validate a model. According to this rationale, a model provides no reason to act unless it is backed by objective data. While we agree that no model can be fully validated until its results can be compared to real data, we nevertheless feel that in many circumstances expert opinions are sufficient grounds for action. In some circumstances (surgery is an example), we must take action on the basis of experts' opinions. If we are willing to trust our lives to expertise, we should be willing to accept expert opinion as a basis for business and policy action. Step 10. Make a ForecastTo make a forecast, we should begin by describing the characteristics of the employees. Given the characteristics of the employees, we use the Bayes' formula and the likelihood ratios associated with each characteristic to calculate the probability of the employee joining the HMO. In our example, suppose we evaluate a 29‑year‑old man earning $60,000 who is computer literate but not an HMO member. Suppose the likelihood ratios associated with these characteristics are 1.2 for being young, 1.1 for being male, 1.2 for having a high hourly rate, 3.0 for being computer literate, and 0.5 for not being a member of an HMO. Likelihood ratios greater than 1.0 increase odds of joining, while ratios less than 1.0 reduce the odds. Assuming an equal prior odds, this employee's posterior odds of joining are: Odds of joining = 1.2 x 1.1 x 1.2 x 3.0 x 0.5 = 2.38 The probability of a mutually exclusive and exhaustive event “A” can be calculated from its odds using the following formula: p(A) = Odds (A) / [1 + Odds (A)] In the above example, the probability of joining is: Probability of joining = 2.38 / (1 + 2.38) = 0.70 The probability of joining can be used to estimate the number of employees likely to join the new HMO (in other words, demand for the proposed product). If there are 50 of the above type of employee, we can expect 35 = (50 x 0.70) to join. If we do similar calculations for other types of employees, we can calculate the total demand for the proposed HMO. Analysis of demand for the proposed HMO showed that most employees would not join but that 12 percent of the employed population might join. Careful analysis allowed the planners to identify a small group of employees who could be expected to support the proposed HMO, showing that a niche was available for the innovative plan. SummaryForecasts of unique events are useful, but they are difficult because of the lack of data on which to calculate probabilities. Even when events are not unique, frequency counts are often unavailable, given time and budget constraints. However, the judgments of people with substantial expertise can serve as the basis of forecasts. In tasks where many clues are needed for forecasting, experts may not function at their best, and as the number of clues increases, the task of forecasting becomes increasingly arduous. Bayes' theorem is a mathematical formula that can be used to aggregate the impact of various clues. This approach combines the .strength of human expertise (estimating the relationship between the clue and the forecast) with the consistency of a statistical model. Validating these models poses a thorny problem because no objective standards are available. But once the model has passed scrutiny from several experts, from different backgrounds, we feel sufficiently confident about the model to ‑recommend action based on its forecasts. What Do You Know?Advanced learners like you, often need different ways of understanding a topic. Reading is just one way of understanding. Another way is through writing. When you write you not only recall what you have written but also may need to make inferences about what you have read. Please complete the following assessment: Biweekly ProjectConstruct a probability model to forecast an important event at work (if you cannot find an appropriate project construct a model to predict breast cancer risks for women 50 years and older. Select an expert that will help you construct the model. Make an appointment with the expert and construct the model. Prepare a Power Point slide presentation that answers the following questions:
PresentationsTo assist you in reviewing the material in this lecture, please see the following resources:
Narrated lectures require use of Flash Download► More & ReferencesReferences
More
Library readings (membership required)
Copyright © 1996 Farrokh Alemi, Ph.D. Created on Tuesday, September 17, 1996. Most recent revision 01/15/2019. This page is part of the course on Decision Analysis lecture on Uncertainty. This page is based on a chapter with the same name published by Gustafson DH, Cats-Baril WL, Alemi F. in the book Systems to Support Health Policy Analysis: Theory, Model and Uses, Health Administration Press: Ann Arbor, Michigan, 1992. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||