|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
HAP 525:Risk Analysis in Healthcare |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Security Risk Analysis
This research was supported in parts by the National Capital Region Critical Infrastructure Project (NCR-CIP), a multi-university consortium managed by George Mason University, under grant #03-TU-03 by the U.S. Department of Homeland Security’s Urban Area Security Initiative, and grant #2003CKWX0199 by the U.S. Department of Justice’s Community Oriented Policing Services Program. The views expressed are those of the authors, and do not necessarily reflect those of the Dept. of Homeland Security or the Dept. of Justice. SummaryWe provide an objective and quantitative method for analyzing risk for unauthorized disclosure of private patient information. The current method, experts generate scenarios of how security or privacy violations might occur and organizations protect themselves against these risks. The current approach leaves healthcare organizations at mercy of vivid imagination of their consultants. In contrast, we propose a method that relies on objective data regarding actual occurrences of privacy violations. The proposed method relies on a National Incidence Database of Unauthorized Disclosures (NIDUD) to identify a small set of risk factors that have led to unauthorized disclosure. Using this set of factors, Health Care Organizations complete a survey and report the frequency of the hazards within their organization. Bayesian probability models are used to compute the overall probability of unauthorized disclosure from survey responses. This paper provides a tutorial on how to do objective risk analysis within health care organizations as well as a test of the concept. We show the application of the approach to four health care institutions. IntroductionHealth Insurance Portability and Accountability Act (HIPAA) and its subsequent final rules[1] require all healthcare providers, their suppliers, contractors and business affiliates to conduct a comprehensive analysis of the risks for unauthorized disclosure. This regulation has caused organizations to rush to analyze risks. Many consultants have emerged with various methods for assessing organization’s vulnerability. In this paper we propose a new method for risk assessment. Our approach is based on the National Incidence Database of Unauthorized Disclosures (NIDUD); in which health care organizations voluntarily report their sentinel HIPAA-related events. The database is used to focus the risk assessment on specific hazards that have occurred in at least one other health care organization. In contrast, today health care organizations conduct risk assessments based on imagined risks that might mislead them to protect against events that will never occur. They may waste precious security funds. Even worst than a one time waste is the prospect that when another consultant, with more active imagination and a more vivid assessment tool, shows up; then the health care organizations is catapulted to invest more -- chasing elusive and esoteric security targets. Since imagination is limitless, there is no end to how much should be spent on security and which vulnerability is more important. Like a child, the organization ends up fighting imaginary foes. Risk assessment instead of helping the organizations focus on high-value targets, misleads them to pursue irrelevant targets. When analysis is based on real vulnerabilities/threats that have led to privacy violations, organization can focus on probable risks and rationally prioritize and limit investment in security controls. Objective analysis of security/privacy risks seems implausible on several grounds. First, privacy and security violations remain rare and therefore assessments of these probabilities are difficult, if not impossible. Second, objective risk assessment is not practical because of extensive data needed. Third, the assessment seems to focus on addressing problems that have arisen in the past and ignores the inventiveness of efforts to break the system. This paper addresses all three criticisms. We show that it is possible to assess rare probabilities from historical patterns, even when the event of interest has happened rarely or even only once. We calculate probability of the event from time-to-the-event (e.g. time-to-computer-theft inside an organization). In this fashion, very small probabilities can be assessed. We show that such estimates can be used to calculate risk of unauthorized disclosure. Are the procedures practical and can they be accomplished in a short time frame by real organizations? Surprisingly, a focus on objective risks reduces as opposed to increase the data collection burden significantly to a small set of risk factors. This makes the objective risk analysis far less time consuming and more practical than a typical comprehensive risk analysis. We show, by way of four examples, how real organizations can assess overall risk and priorities quickly and based on objective data. The last concern with objective risk analysis focused on preparing against inventiveness of people who want to break the system. The proposed objective analysis does not prepare against all possibilities and leaves the organization partially vulnerable. But no one can plan against unknown risks; neither our proposed approach nor the existing state of the art of doing everything possible protect us against the unknown. No analysis, no matter how comprehensive, can anticipate unknown risks. Objective risk analysis is useful in creating market-based incentives for improving privacy of patient health information. If accurate methods for assessing probability of unauthorized disclosures existed, then insurers can offer products for coverage of HIPAA liabilities. Then, the premiums for HIPAA insurance will create market incentives for organizations to improve their privacy and security. Organizations with a poor track record will face higher insurance premiums and those with adequate security safeguards will face lower premiums. This paper provides procedures for conducting probabilistic risk rating from experiences of various organizations; thus it provides a first step in offering HIPAA insurance. HistoryThe methodology for probabilistic risk analysis has evolved over the years through its application in the aerospace, nuclear power, and the chemical industries.[2] The Health care industry can build its risk assessment procedures based on progress made in these industries. A key feature of risk assessment procedures in these industries has been a cumulative database of hazards and scenarios from accidents or near-accidents. For example, following Challenger disaster, the National Aeronautical and Space Administration had to revise its procedures for risk assessment to include scenarios previously not considered in the predictive models and to correct and revise the probabilities of other types of failures.[3] Similarly, after the Three Mile Island nuclear accident, risk assessment procedures had to be revised and the probabilities associated with human error had to be significantly increased.[4] Experiences of other industries highlight the need to take an evolutionary approach to risk analysis, to share information across organizations and to increase the knowledge base by allowing each incidence of unauthorized disclosure to inform us of emerging hazards. In this paper, we show how one can use the procedures for risk analysis in these industries to healthcare. Like these industries, we propose the creation of a centralized repository of possible adverse events. Need for a National Incidence DatabaseWe propose an objective methodology that utilizes cumulative experience, over time, thereby allowing the accuracy of the predictions to increase with use. To accomplish this goal, we propose to build a blinded incidence database of unauthorized disclosures. Joint Commission on Accreditation of Health Care Organizations has created a similar database for sentinel events (e.g. medication errors or wrong side surgery). If Joint Commission would consider privacy violations as a sentinel event, its database can serve as the repository for our proposed method. Until a national repository is organized, we can rely on publicly available sources (complaints to Federal government, court cases and news reports) to organize one such database (See Figure 1). The database is used to (1) define the focus of risk analysis, and (2) calculate the frequency of various risk factors among cases leading to unauthorized disclosures.
Figure 1: Sources of Data If an ongoing national database existed, analysts can use it to expand their risk scenarios to include all known relevant risk factors. The moment a new hazard is identified in one part of the country; all subsequent risk analysis could include it -- providing a rapid method of improving risk assessments. MethodsThe probability of unauthorized disclosure can be measured from a list of risk factors using the following formula: p(U| R1, …, Rn )= ∑ i=1, .., n p(U | Ri) p(Ri) Where:
This formula is known as the law of total probability and it states that the probability of an unauthorized disclosure is the sum of all ways in which an unauthorized disclosure can happen from different risk factors within the organization. We estimate the frequency of risk factors within an organization, p(Ri), by surveying key informants within the organization. Since privacy risk factors can be rare, we assess the probability of their presence from the average time between reported occurrences of the risk factor:[1] p(Ri) = 1 / (1+ ti) Where,
Use of this formula assumes that the risk factor has a binomial distribution of occurring in which the probability of the risk factor is relatively rare but constant and independent from future occurrences. These assumptions may not be reasonable. For example, when organizations actively improve their security, then the assumption of constant probability is violated. If the assumptions of binomial distribution are met or are acceptable as a first approximation, then time-between presence of risk factor has a geometric distribution. In a geometric distribution, the relationship between time-between events and probability of the event are given as per above formula. Some risk factors are so rare that they may not occur during the observation period. In these circumstances, then length of observation period can be used as a surrogate for time-between reoccurrences. This assumes that the risk factor would occur the day after the end of observation period and thus it provides an upper limit for the prevalence of the risk factor. For an example of the use of the formula consider if we were to asses the prevalence of “physical theft of a computer.” Suppose that our records show that such theft occurs once every three months, then the time between two thefts is 90 days and the probability of a theft for any day is calculated as: p( Physical theft of a computer) = 1 /(1+91) = 0.01 This method of calculating prevalence of hazards stands in contrast to the arbitrary classification of risks by others. For example, the International Organization for Standardization (ISO) on December 2000 ratified the standard 17799 for management of information security. The authors of this standard proposed to measure risk using the scale in Table 1. Table 1 also reports our approach to quantification of same scale. Clearly, the ISO 17799 standard does not accurately reflect the probability of the reported events. In fact, the correlation between ISO 17799 rating and calculated probabilities is 0.69, showing a moderate relationship between the two estimates.
We use the Bayes theorem to calculate the probability of unauthorized disclosure after the occurrence of a risk factor: p(U | Ri) = p(Ri | U) p(U) / p(Ri) Where:
For example, if probability of unauthorized disclosure across organizations is 0.5% and the probability of observing computer theft is 1%, and the proportion of unauthorized disclosures attributed to computer theft is 2%, then the conditional probability of unauthorized disclosure following computer theft is 0.02*0.05/0.01 = 0.10 . ResultsIn the absence of the National Incidence Database of Unauthorized Disclosures, we could rely on publicly reported privacy violations to show how our proposed method will work. We identified publicly available reports of unauthorized disclosures from (1) review of complaints to Department of Health and Human Services regarding privacy issues, (2) Legal and news databases for reports of unauthorized disclosures. Table 2 shows the term used to search for unauthorized disclosures and the number of unique cases found:
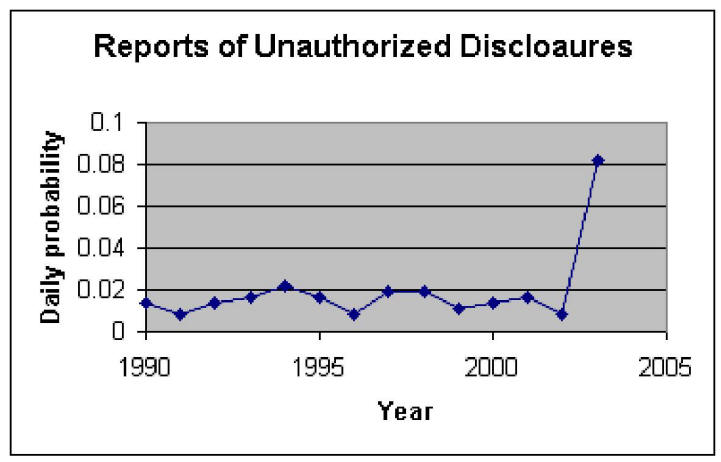
For each case of unauthorized disclosure in our database, we described a risk factor that organizations could have reduced through security controls. A comprehensive list of experienced hazards we identified through review of publicly available reports of unauthorized disclosure is available in Table 3. Obviously, security professionals may list many more vulnerabilities but these may not have yet occurred anywhere. We estimated the probability of an unauthorized disclosure by examining the frequency of reports of unauthorized disclosures in legal, news and complaint databases. These frequencies respectively were: 0.009, 0.006 and 0.003 per day. The overall probability of unauthorized disclosure across all sources was 0.019. Figure 2 shows the change in reported rates of unauthorized disclosures over the last decade. There is a significant increase in the rates in 2003, when DHHS started collecting complaints.
The operation failed. If this continues, please contact your server administrator.
The operation failed. If this continues, please contact your server administrator. Database Results Wizard Error The operation failed. If this continues, please contact your server administrator. DiscussionThis paper proposes a method for assessing risk of unauthorized disclosure within a health care organization. It shows a mathematical formula for how to combine data on prevalence of hazards at health care enterprises with conditional probabilities estimated from the database of unauthorized disclosures. The advantages of the proposed approach are:
For this approach to risk assessment to work, we need a centralized database of incidences of unauthorized disclosures. We did not have access to such a database but showed that the information can be assembled from public records of court proceedings, news reports, and complaints to Department of Health. Are the procedures described practical? The data needed at the enterprise level is minimal. Most organizations have a data set of security incidence categorized by type of hazard and catalogued by date of occurrence. The creation of the cumulative national incidence database is more difficult. While we succeeded in creating it from public records, a more reasonable approach is to ask institutions to report these data to a central location, perhaps to the Joint Commission for Accreditation of Health Care Organization. The database calls for collaboration among health care institutions that may currently compete and perhaps may be concerned with the security of the data they share. We believe safeguards could be put in place that would protect individual institution’s identity. The benefit of such database outweighs its potential problems. In the absence of incidence database, risk analysis for HIPAA will not be consistent across organizations and may involve considerable effort and speculation about events that have not occurred or do not matter. Many organizations may not even conduct quantitative risk analysis and may settle for vague and arbitrary qualitative measure of low, medium and high risk. The incidence database can pool information from a large number of organizations so that it has sufficient cases to estimate various probabilities. The HIPAA legislation and final HIPAA rules already require organizations to maintain logs of every disclosure. The incidence database centralizes this information and allows the organization to use the information in a collaborative fashion to conduct its risk analysis. In the process of these collaborations, organizations learn about best practices. References[1] Centers for Medicare & Medicaid Services (CSM), HHS. Health insurance reform: security standards. Final rule. Fed Regist. 2003 Feb 20;68(34):8334-81. [2] Bedford T, Cooke R. Probabilitistic risk analysis: Foundations and methods. Cambridge University Press, Cambridge United Kingdom, 2001, 4-9. [3] Colglazier EW, Weatherwas RK. Failure estimates for the space shuttle. Abstracts of the Society for Risk Analysis Annual Meeting 1986 Boston MA, p 80, Nov 9-12, 1986 [4] Keeney J et al. Report of the President’s Commission on the Accident at Three Mile Island, Washington DC 1979. Presentations
What Do You Know?This section is under development. More
This page is part of the course on Risk Analysis. This presentation was based on Alemi F, Shahriar B, Shriver J, Arya V. Probabilistic Risk Analysis (in review) . For assistance write to Farrokh Alemi, Ph.D. Most recent revision 10/22/2011. This work has been supported by grant from Critical Infrastructure Protection project. This paper reflects the opinions of the authors and not necessarily the policies and practices of their organizations. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||