|
 |
||
|
|
||
Introduction to Data IntegrationIntroductionThis course is aimed at teaching you how to perform data integration, i.e., the merging of two or more disparate data sources into a single coherent data set to support the information needs of the target business or enterprise. The methods and procedures described herein are based, and, take advantage of the power of XML and the robustness of the tools available to manipulate data once it has been 'tagged' in accordance with the XML syntax. It is recommended that you read all sections in the order in which they are presented since the examples and techniques of each new chapter build on those introduced in the preceding ones. No in-depth knowledge of database design, data modeling or programming is required but a certain familiarity with them is definitely an asset. To make the most of it you should have access to a computer running Windows or some other operating system such as Linux and you should have a suite of office tools capable of performing word processing, spreadsheet manipulations and basic database operations, e.g., MS Office or Star Office. Finally, you should also have an XML-enabled browser such as Internet Explorer version 5.0 or higher. ContentsPart 1�
Part 2—
Part 3�
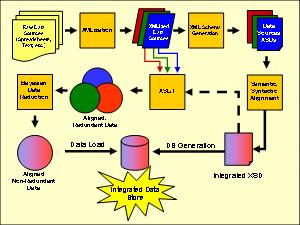
Statement of the ProblemHealth care providers collect and maintain large quantities of data. Except for rare cases the structure of the data of one health care provider bears no similarity to the structure of any other one. Yet data communication and data sharing is becoming more important as organizations see the advantages of integrating their activities and the cost benefits that accrue when data can be reused rather than recreated from scratch. Given this diversity of data sources, how does one efficiently and reliably integrate them? One approach, described in this book, is to leverage the power and ease of implementation of eXtensible Markup Language (XML) technologies to accomplish that goal. Role of XML TechnologiesFigure 0-1 below depicts the roles and steps necessary to accomplish data integration using XML technologies. According to this methodology the first step consists in taking the raw data sources—spreadsheets, text, etc—and converting them into well-formed XML documents. This is needed to take advantage of all the other XML technologies which will enable the health provider to integrate relevant data for its organization. Once data has been XMLized the next step is to analyze and document its structure. Within the context of XML technologies this is done by creating the XML schemas (XSD) for each of the data sources. As we will see, this is basically another form of doing data modeling, i.e., understanding and specifying the semantics and syntax of the data, as well as their relationships. Once the different XSD’s—i.e., the ‘data models’—for each of the data sources are available the health care provider can begin to align them and generate a single integrated XSD, i.e., an integrated data model for all of them. Out of this XSD we can create both the target data base as well as the specifications for how to recast the XMLized data sources in terms of this new vocabulary. This transformation from the original data structure into the target data structure is readily carried out with another XML technology, namely, XML Style sheet Language/Transformation (XSL/T). Once the data transformation has taken place the data sources will have a consistent, common structure but most likely may not be completely free of redundancies. The assessment of data overlap and its elimination can be automatically performed using machine learning algorithms. In this book we describe how a Bayesian predictor approach can determine which records are duplicate and, therefore, need to be removed from the final data pool.
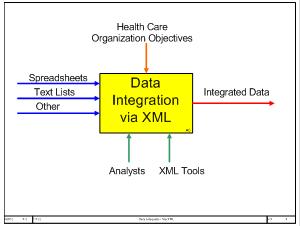
Figure 0-1. XML Technologies for Data Integration Roadmap Once the transformed source data is free of duplications the health care provider can proceed to upload it into the target data base. In this book we show how XML can also facilitate data upload into data store. Data Integration Activity ModelFigure 0-2 below shows the context activity diagram for the entire data integration activity model using the IDEF0 notation. The inputs (arrows coming into the box from the left) for this process are the raw data sources, which can be spreadsheets, text lists (e.g., tab delimited, or comma delimited files), as well as any other type of ASCII file containing the data that needs to be integrated. The controls (arrows coming from the top into the box) are the goals and objectives that a given health care provider has with respect to the data to be integrated. The output (arrow exiting the box on the right) is the fully aligned and integrated data once it has undergone the data integration process. The mechanisms (arrows coming into the box from the bottom) are the resources required to accomplish the stated activity.
Figure 0-2. XML Technologies for Data Integration Roadmap SummaryData sources constitute a valuable asset for health care providers. As these organizations coordinate and combine their activities they need to be able to reuse their data. Because in most cases data sources are structured in dissimilar ways the health care provider must first integrate them. XML technologies provide an easy and efficient way for accomplishing this goal. Most data sources can be XMLized in a few simple steps. Once in that form their structure can be defined and documented in the form of schemas (XSDs). From the individual XSDs the health care provider can generate a common, integrated specification of the semantics and syntax for all the pertinent data sources. This specification can generate not only the physical target data base, but serves to specify the transformations to recast the source data in a form conformant with the new semantics and syntax. This step is accomplished using XSL/T. The final step prior to loading the data is to remove redundancies. An efficient way to do this is to use Bayesian predictor methods. Once the source data is free of redundancies it can be loaded into the target data repository. This step can also be accomplished using XML since most commercial RDBMs are now capable of automatically importing XML documents. PresentationsFollowing resources are available:
Narrated lectures require use of Flash . What do you know?Before we get started, it is important to make an inventory of what you know so that by the end you can better understand your progress. Please take the following brief self assessment. More
This page is part of the course on Data Integration , the lecture on Introduction to Data Integration. This page was last edited on 10/22/2011. ©Copyright protected. For more information contact us. |
||