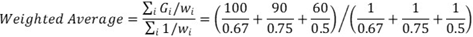|
 |
HAP 719: Advanced Statistics I |
|
|
Analysis of Co-Variance & Covariate BalancingObjectivesAfter completing the activities this module you should be able to:
Lecture
AssignmentsAssignments are submitted on blackboard. They are graded as pass/fail. A summary 1-page word document should be included. In the summary, you should state if you were able to get the same answers as those provided. Your R, STATA, or Python code should be included in separate files. No late assignments are accepted. It is OK to help each other in doing the assignments but not OK to copy and paste work of others. It is OK to use ChatGPT or other large language models to generate the R code, but you must be transparent about it and report its use. The data set you will be using for this project constitutes a subsample of a larger data set called 2011/2012 National Survey of Children’s Health (NSCH) which was conducted by the Centers for Disease Control and Prevention (CDC) and the National Center for Health Statistics. This survey included around 95,000 children between the ages of 0-17 years and its purpose was to measure children’s health status, insurance coverage, parental health and several other characteristics.
Question 1: The following data provide the length of stay of patients seen by Dr. Smith (Variable Dr. Smith=1) and his peer group (variable Dr. Smith = 0).
Question 2: The following data show the grades students got while working in teams. Estimate what should be the grade of each student, controlling for who they teamed up with. Here's how you can proceed. The grade for each student is a weighted average of their project grades. The project grades are weighted based on the team member's likelihood to increase the team's grade. For example, to calculate if Student B increases Student A's grade, you can count the number of projects where Student B was present and the grade was above average of all project grades. Then, divide this count by the total number of projects that student B had done: Count teams where Student B was present and grade was above average of 83.75: 2 (project 1 and 2) Count projects where Student C was present and project's grade was above average grade of 83.75: 3 Count projects where student D was present and project's grade was above average of 83.75: 2 Separate analysis must be done for each student. Here is an example of Inverse Propensity weighted average score for student A:
Calculate the inverse propensity weighted grades for all students. .
Question 3: The following data provide the relationship between Y and variables A, B, C, and D. Create an interaction plot, to examine the interactions between variables B, C, D and the variable A. More
|
|