
Generated by ChatGPT
Overview
This section provides more details on construction of regression models.
In this module, you will dive into the construction of regression models,
a critical aspect of statistical analysis. You will examine whether a
combination of variables serves as a more accurate predictor than each
variable individually. Additionally, you will distinguish among several
methods of building a multiple linear regression model, including those
with interaction terms. By interpreting findings from statistical outputs
related to these techniques, you will gain a comprehensive understanding
of regression model building, enhancing your ability to make informed
decisions based on your analyses.
Learning Objectives
After completing the activities this module you should be able to:
- Examine if combination of variables are more accurate predictor
than each variable by itself.
- Distinguish among several methods of building a multiple linear regression model,
including models with interaction terms
- Interpret findings from statistical outputs pertaining to a regression model building technique
Lecture
 AI
assisted content, image, or video AI
assisted content, image, or video
- Statistical Analysis of Electronic
Health Records by Farrokh Alemi, 2020, pages 274 through 281
Slides►
Video►
- Coefficient of Determination using R software
Read►
- Model selection using R software
Read►
- Yili Lin's on model building and selection
Slides►
Video
1►
Video
2►
- Yili Lin's Model building using R
Slides►
Video►
Assignments
Assignments should be submitted in Blackboard. The submission must have a summary statement, with one statement per question. All
assignments should be done in R if possible.
Question 1: The following data provide a large number of factors that affect vaccination rates for COVID-19 in a county in
United States. Use hierarchical modeling to see which subset of factors explain largest portion of variance in getting Complete Series Vaccination rate.
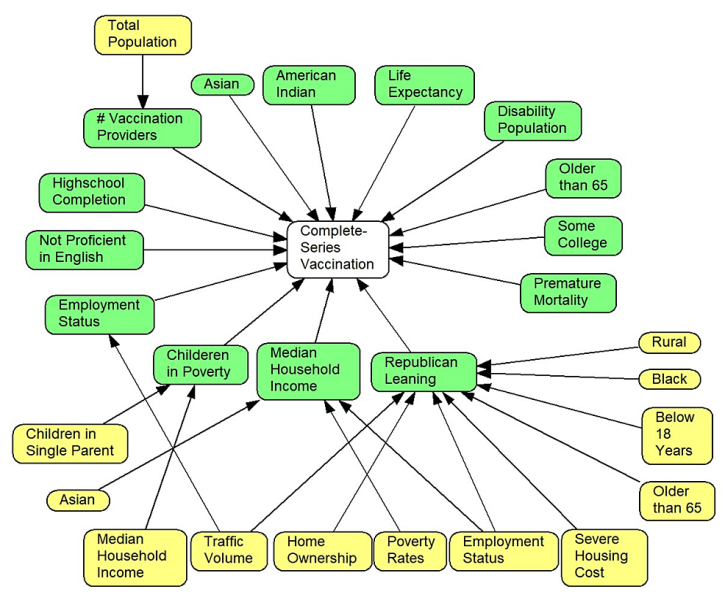
- Initially explain variation in Complete Series Vaccination rates by demographics (including age, race, gender) of the county's residents.
Report the percent of variation explained.
- Explain variation in Complete Series Vaccination rates by demographics (age, race, gender), and social determinants (including high school
completion rate, percent nor proficient in English, percent employed, percent of children in poverty, and median household income).
Report the percent of variation explained.
- Explain variation in Complete Series Vaccination rates by demographics (age, race, gender), social determinants (including high
school completion rate, percent nor proficient in English, percent employed, percent of children in poverty, median household income) and health of residents
(including percent population disabled, life expectancy, percent population having premature morbidity). Report the percent of variation explained.
- Explain variation in Complete Series Vaccination rates by demographics (age, race, gender), social determinants (including high school completion rate,
percent nor proficient in English, percent employed, percent of children in poverty, median household income), health of residents (including percent population disabled, life
expectancy, percent population having premature morbidity), and political leaning of the population (including republican leaning,
democrat leaning). Report the percent of variation explained.
- Does a county's political leaning affect vaccination rates?
Resources for Question 1:
Question 2: The following data provide a large number of factors that affect diabetes rate in a county in United States.
Use hierarchical modeling to see which subset of factors explain largest portion of variance in rate of diabetes in the county.
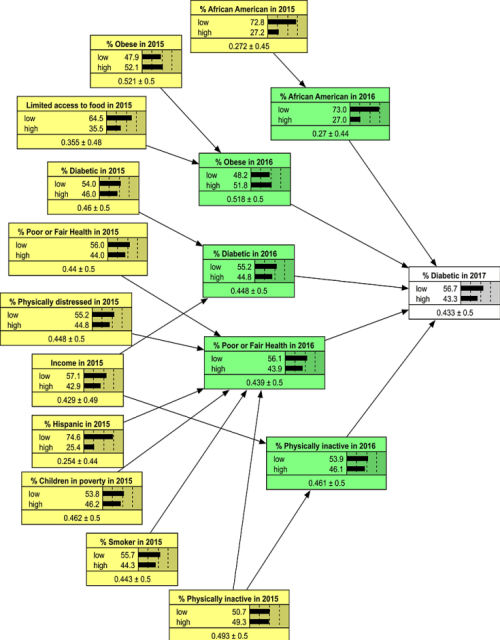
- Using only independent variables measured in 2015 predict incidence of diabetes in the county. Report the percent of variation explained.
- Using only independent variables measured in 2016 predict incidence of diabetes in the county. Report the percent of variation explained.
- Using both independent variables measured in 2015 and independent variables measured in 2016, predict incidence of diabetes in the ocunty. Report the percent of variation explained.
- List variables that have have an impact on incidence of diabetes within a year.
- List variables that have an impact on incidence of diabetes within 2 years.
Resources for Question 2:
More
For additional information (not part of the required reading), please see the following links:
- Open Intro's model building lecture
YouTube►
- Introduction to regression
YouTube►
Slides►
This page is part of the HAP 719 course on Advance Statistics I and was organized by Farrokh Alemi PhD Home►
Email►
|
