
Assigned Reading
- Session overview
YouTube►
- Read Chapter 12 in Statistical Analysis of Electronic Health Records by Farrokh Alemi, 2020
- Calculate McFadden R-squared
ChatGPT►
- What to do when McFadden R-squared is negative? ChatGPT►
- Dummy coding for categorical data
ChatGPT►
- Replacing logistic regression with ordinary regression
Slides►
YouTube►
Video►
- Convert STATA code to R
ChatGPT►
- Detecting interaction terms using stratification and contour
plots Slides►
- Use of corner cases to specify logistic regression's
coefficients
Slides►
- More on missing values
Read►
Slides►
Assignment on Introduction to Logistic Regression
Assignments should be submitted in Blackboard. Include a summary page. In the summary page,
write statements comparing your work to answers given or videos. For example, "I got the same answers as the Teach One video for question 1."
Or you can write: "There was no answer sheet available for question 2." We prefer that assignments are done in R.
First Week Introduction to Logistic Regression Question 1: Use the following corpus of training data. Classify if the target sentence is a complaint. The corpus is organized
as in the following table. The comment ID shows the comment in the training data. In the following table, 6 comments in the training set are displayed.
The columns on the right of the table show where in the training comment the words from the target comment appears.
For example, in the training comment 57685 the word "patient" in the target comment is the third word in the training comment.
comment
Id |
Type
Id |
Classification
True = Complaint
False = Praise |
loves |
patients |
tell |
about |
not |
money |
|
57685 |
1 |
TRUE |
0 |
3 |
0 |
2 |
0 |
0 |
|
57688 |
1 |
TRUE |
0 |
0 |
1 |
0 |
0 |
0 |
|
57703 |
1 |
TRUE |
0 |
0 |
0 |
0 |
0 |
9 |
|
57704 |
1 |
TRUE |
0 |
0 |
0 |
3 |
0 |
0 |
|
57711 |
1 |
FALSE |
0 |
8 |
0 |
0 |
0 |
0 |
|
57712 |
1 |
TRUE |
0 |
0 |
0 |
0 |
2 |
0 |
In the following, calculate predicted value of a logistic regression
using the following formula:
- Regress the classification labels in the training set on the words, pair of consecutive words, and triplets of consecutive words in the target
sentence: "He loves his patients and I can tell it's about us and not the
money." Use the predicted probability of complaint to classify the target sentence. Values above 0.5
should be classified as complaints.
- Regress the classification labels in the training set on the
words, pair of words, triplet of consecutive words in the target
sentence "However, I am not happy with rhinoplasty revision results."
Use the predicted probability of complaint to classify the target
sentence. Values above 0.5 should be classified as complaints.
- Repeat the analysis but this time include all of the
complaints and 50% random sample of praises in the training data set.
How did the sampling procedure affect the McFadden R-square
Resources:
- Labeled training data set for: "He loves his patients and I can
tell it's about us and not the money."
Download►
- Labeled training data set for: "However, I am not happy with rhinoplasty revision results."
Download►
- How to predict response variable in logistic regression
ChatGPT►
- How to drop variables that are perfectly correlated?
R Code►
- Full Corpus (needed for analysis of other target comments)
Download►
Preprocessing
ChatGPT►
- Vladimir Cardenas's
Answer►
R Code►
- Regina Reyes's Teach One
on "However, I am happy with rhinoplasty revision results."
Slides►
YouTube►
- Sravya's Teach One on "He loves his patients and I can tell it's about us and not the money."
Slides►
YouTube►
First Week Introduction to Logistic Regression Question 2: Regress survival in next 6 months on disabilities of the patients, age of patients, gender of patients and
whether they participated in the medical foster home program. MFH is an intervention for nursing home patients. In this program, nursing
home patients are diverted to a community home and health care services are delivered within the community home. The resident eats with the
family and relies on the family members for socialization, food and comfort. It is called "foster" home because the family previously
living in the community home is supposed to act like the resident's family. Enrollment in MFH is indicated by a variable MFH=1.
Survival is reported in two variables. One variable indicates survival in 6 months. Another reports days known to survive,
if the patient has died and otherwise null. Thus a null value in this latter variable indicates the patient did not die.
The functional disabilities are probabilities that the patient has the disability. These probabilities are generated from the CCS diagnoses and demographics of the person.
Use long term disabilities. These are the disabilities with suffix 365. If the disability is higher than 0.5, then assume the person is disabled.
- Clean the data. Convert the disabilities to binary variables. Convert the age to decades
- Create a regression model to explain the relationship among the variables and survival.
- List the top 4 predictors of survival (list these predictors using English language and not coded data).
- Describe, in English, if the MFH program contributes to survival. Provide the evidence for your claim.
Resources:
First Week Introduction to Logistic Regression Question 3: Predict
from age, gender, symptoms, home test results the
PCR test results for COVID-19.
- Build a model that includes only "home test results" as
independent variable. Report the percent of variation explained
- Build a model that includes age and gender, interaction of age and
gender, and home test results as independent variables. Report the percent of variation explained.
- Build a model that includes age and gender, interaction of age and
gender, home test results, and symptoms as independent variables. Report the percent of variation explained
- Build a model that includes includes age, gender, interaction of
age and gender, symptoms, home test, and pairs of symptoms, as independent variables. Report the percent of variation explained
- What is the most accurate way of diagnosing COVID-19 at home prior
to triage to clinics?
- Can a clinician learn to make these diagnoses or is the number of
adjustments needed beyond human capabilities?
The following resources may be helpful:
Second Week: Assignments on Missing Values and Logistic Regression
Second Week Missing Values in Logistic Regression Question 1: The following data provide the length of stay of patients seen by Dr. Smith (Variable Dr Smith=1) and his peer group
(variable Dr. Smith = 0). Does Dr. Smith see a different set of patients than his peer group? In particular, what is the
probability of patients being seen by Dr. Smith. Regress the choice of provider on the 9 diagnoses provided.
Resources:
Second Week Missing Values in Logistic Regression Question 2: In a nursing home, data were collected on residents' survival and disabilities. The data are
listed in the following order: ID, age, gender (M for male, F for Female), number of assessments completed on the person, number of days
followed, days since first assessment, days to last assessment, unable to eat, unable to transfer, unable to groom, unable to toilet, unable to
bathe, unable to walk, unable to dress, unable to bowel, unable to urine, dead (1) or alive (0), and assessment number.
Predict from the patient's assessments (i.e. their age and current disabilities at time of assessment) if the patient is likely to die. Here are the steps in this
analysis:
- Read the data, making sure all entries are numbers.
- Calculate age at each assessment not just at first assessment.
- Clean the data, removing impossible situations (remove cases with date of assessment after death).
- Remove irrelevant cases (all cases that have only one assessment)
- Organize age at current admission into a binary variable above or below the average age at current assessment.
- Estimate missing values
- Regress death in 6-months on various current disabilities, age,
gender, and pairwise interactions of these variables.
Resources:
Third Week: Assignments on Model Building and Logistic Regression
Third Week Model Building in Logistic Regression Question 1: In a nursing home, data were collected on residents' survival and disabilities. The data are
listed in the following order: ID, age, gender (M for male, F for Female), number of assessments completed on the person, number of days
followed, days since first assessment, days to last assessment, unable to eat, unable to transfer, unable to groom, unable to toilet, unable to
bathe, unable to walk, unable to dress, unable to bowel, unable to urine, dead (1) or alive (0), and assessment number. Predict from
the patient's assessments (i.e., their age and disabilities at time of assessment) if the patient is likely to die and should be admitted to
the hospice program.
Resources for Question 1:
Third Week Model Building in Logistic Regression Question 2:
Regress incidence of diabetes on all other body-system variables
(including pairwise, and triplet of variables) and indicator variables
for missing variables. You can do the analysis first on 10% sample
before you do it on the entire data that may take several hours.
- Create a binary variable that is 1 every time a variable is missing and 0 otherwise. Predict
diabetes from patterns of missing binary variables.
- Create binary variables for missing values.
- Calculate number of variables that are missing for each case
- Create a cascaded data, where cases are arranged in order of
number of variables missing. Put all missing variables last.
- Create interaction terms for missing indicators so that the
interaction term corresponds with patterns of missing variables in
the cascaded data.
- Test the statistical significant of missing indicators and
interaction among missing indicators.
- Report the percent of variation in incidence of diabetes
explained by patterns of missing variables
- Regress diabetes on body systems, pairs of body systems, triplets
of body systems, and statistically significant patterns of missing
values. Report the coefficients and the percent of variation explained.
One way to reduce the number of independent variables is to drop body
systems that are always missing. When a variable is always
missing, then regression software automatically drop these variables.
You can save computation time by dropping the variables before
analyzing the data. The plot below shows body systems and extent
of missing values within them.
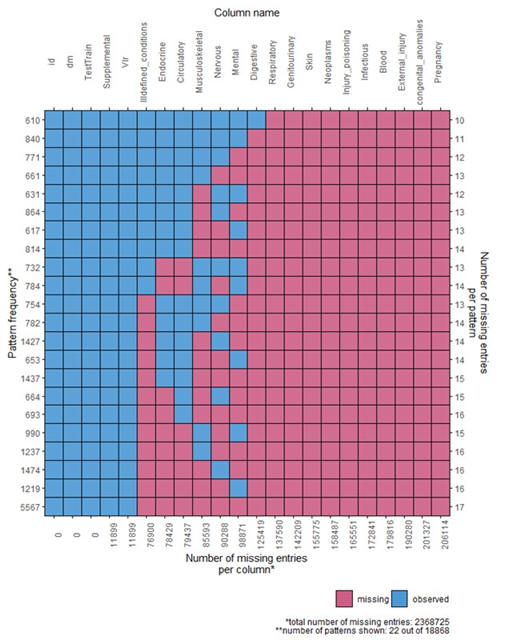
Resources for Question 2:
This page is part of the HAP 819 course on Advanced Statistics by Farrokh Alemi PhD
Home►
Email►
|